【聊聊MySQL】六.MySQL-InnoDB的数据库事务背景_BufferPool
该文章采用先各个概念理解然后在最后可以配置各个不同参数的方式。所以如果想要配置的时候,可以直接看最后一个章节。
一. BufferPool总览
之前在 MySQL-InnoDB体系结构 中有说过,InnoDB 有一个一直在运行的后台线程在跑,目的简单的说就是 异步的同步内存中的数据到硬盘上去。 那进一步说为啥要同步,因为内存中的数据已经发生修改,所以这就是接下来的内容,从修改数据开始讲起。但是之前我们需要先了解一下 BufferPool 的出现。
二. BufferPool查询数据的作用
那为啥要使用 BufferPool 捏,这就是从 BufferPool 本质说起。我们在开发的时候,如果为了提速查询功能,通常会用到一个东西,叫做 缓存。 缓存 怎么理解,我们知道,硬盘里面存储着我们的文件,但是程序如果需要读取硬盘上的信息,就需要通过系统 IO 将硬盘上的数据放进去内存中,然后程序才可以使用。如果一个查询很频繁,每次都做这个动作的话,IO 消耗的时间将会很大,而且这个过程除了读取数据之外,其实没有多大的意义,它发生一次就好了,所以我们会把这部分程序经常要 读取的 数据放在 内存 中,程序通过 系统API - 电线 读取内存中这部分热数据就好了,这样就起到了提速的效果。那么这部分在内存中的热数据称之为 缓存。 那 BufferPool 就是这个缓存了。 前面我们唠叨那么多查询的过程,可以简单的认为就是我们业务查询逻辑的过程,查询到数据丢到缓存(BufferPool)在没有被缓存淘汰的情况下查询这部分数据,就可以直接的从缓存中捞出来返回了,所以第一次查询通常要比后面运行的查询慢,因为需要经历这个过程。
三. BufferPool更改数据的作用
那 BufferPool 在数据库中作为缓存的时候,在修改数据时发生的事情又跟我们的程序不一样。我们的程序通常是先修改数据库数据,保证成功以后,再清理缓存。这样就算缓存系统(通常是 Redis)崩了我们的程序还可以接着从数据库读取,并不会太大的影响程序的运行。 但是 BufferPool 就厉害了,他不仅在查询的时候当缓存的角色,在增删改的场景下也是一个当缓存的角色。 怎么做的,当客户端告诉数据库要更新的数据的时候,BufferPool 也是加载数据所在的页,将修改的数据更新到 BufferPool 中。在后面某个时刻需要同步 BufferPool 数据页到磁盘的时候,还发生一个动作,就是将修改后的数据页拷贝到内存中的日志缓冲之中,日志缓冲再按照 一次 1m,两次写入 将修改的数据同步写入共享表空间中(并不是表所在的表空间),而写共享表空间的时候,因为是顺序写入,不需要考虑调整 索引B+树 的平衡,所以写入将会很快。因为这个数据页被两次写入硬盘中,所以这个过程称为 Double Write。 那么我们修改数据的时候发生了什么事情:
- 数据库接收到
Commit命令(没手动开启事务的话系统也会自动加上去)的时候,将REDO LOG同步写入磁盘; -
BufferPool加载需要修改的页,在BufferPool中发生修改,然后在前面文章所说的While-True循环中,在某个时刻写入磁盘; - 在某个数据页需要写入磁盘的时候,执行
Double Write的逻辑,就是先将数据页写入共享表空间中; - 开始同步数据页到真正的表空间中,这时候需要同步到硬盘的数据是离散的,因为可能需要修改索引(非聚集+聚集)。
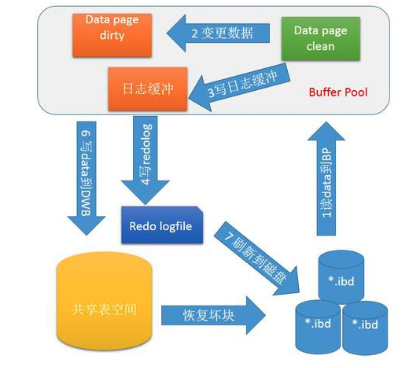
图片来源:MySQL double write 那为啥有 REDO LOG 还需要这个 Double Write 呢,原因就是,REDO LOG 的日志格式,他记录着哪一页修改了什么东西,问题就出在数据页是 16kb 的,在写盘的时候,由于系统每次写一页是 4kb,磁盘一次 IO 是 512 byte。那如果在写入数据页的时候,突然发生意外,那磁盘中的数据页可能被破坏了(16kb 只完成了 10kb 的同步 ),而 REDO LOG 是针对数据页做修改做记录的(比如第几页将第一条记录的 a 列从 1 改成 2),那即使有 REDO LOG 他也不敢对一个坏的数据页做修复了。这时候 Double Write 写在表共享空间中的数据页就发生了作用,数据库可以将共享空间中的已经修改完成的数据页还原然后进行重做了。
四. BufferPool内部组成
现在我们知道 BufferPool 在 MySQL 中他可是 CRUD 的主要主角,功能不局限于查询数据的时候,缓存数据页的功能,也包含了在修改数据的时候,先修改 BufferPool 中的数据,等待一个循环的线程在某个时刻将数据同步到真正的表空间中。 那么在 BufferPool 中存在哪些东西,我根据标题来展开说说:
4.1 BufferPool数据页链表
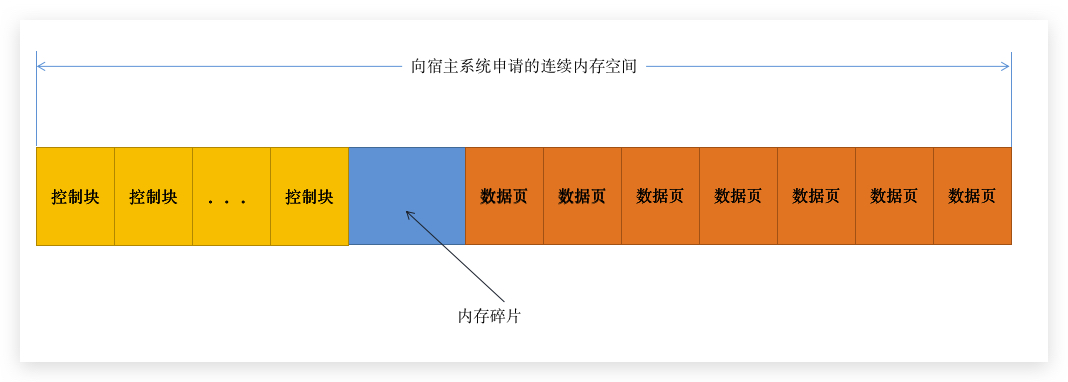
首先,BufferPool 有一块连续的内存空间:

空间里面,就被分割成几个部分:数据页控制块、缓存页、以及一些没有任何作用的内存碎片(就是剩余空间不足以分配一个数据页的内存空间):
控制块包含了很多信息(要不然为啥被独立出来):包含数据页的表空间号、页号、缓存页的地址、锁信息、LSN 等等信息,我这里列了几个我们后面会用到的玩意儿。 因为有缓存页的地址,所以图会有个箭头(我只画了一个箭头):
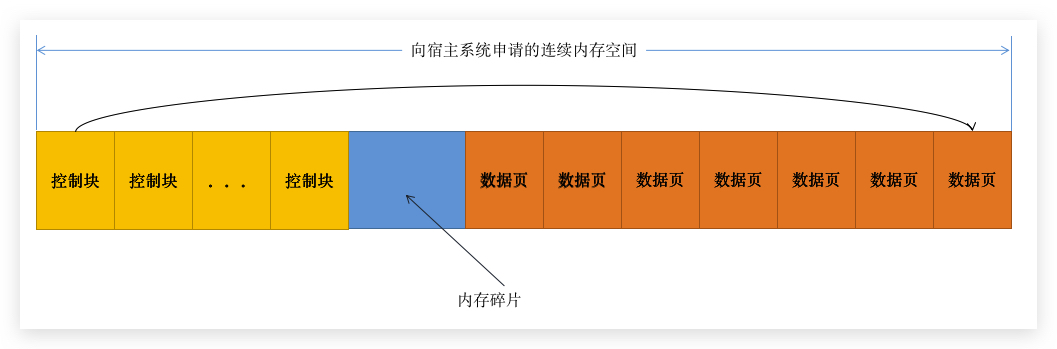
那数据库系统在启动的时候,就会自动的分配 BufferPool 空间,将控制块和数据页的位置规划好以备后续使用。
4.2 BufferPool 的 free 数据缓存链表
OK,镜头深入一下控制块:
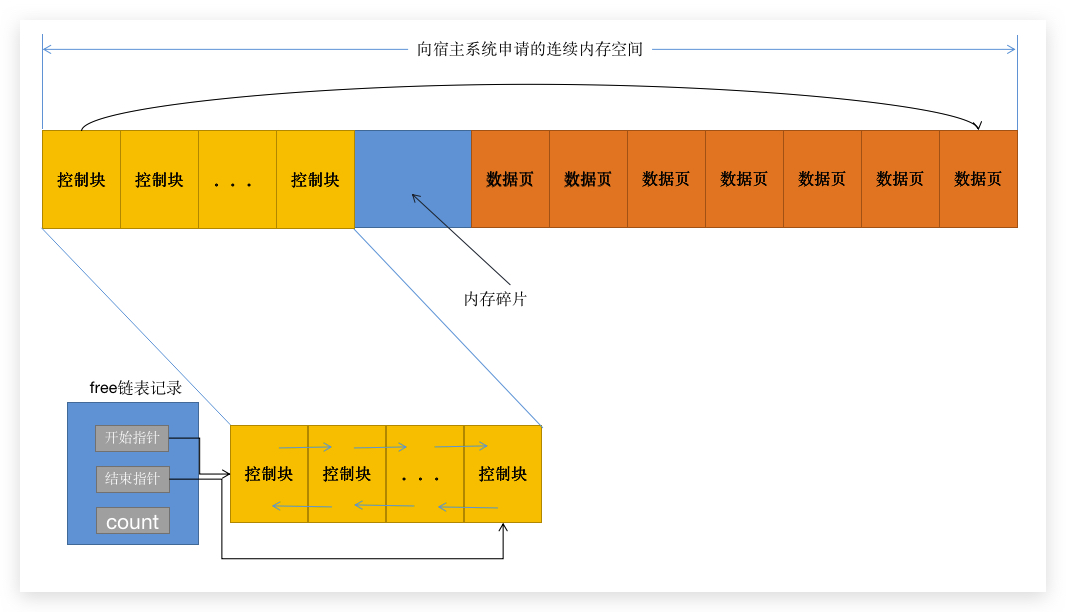
那怎么管理链表呢,有个链表记录,记录谁有空,然后可以将空的控制块信息放入一个双向链表中,这时候如果数据库需要一个缓存页,可以从这个链表取出一个空闲的控制块进行操作,而管理空闲链表这边将会把这个控制块移除标(相当于记为已经使用) 那在查询数据的时候,我们知道查询的时候是加载索引来查询的,比方说:
1 | SELECT * FROM student WHERE stu_id = xxx; |
那 MySQL 肯定需要加载 B+ 树来查询的嘛,那就需要先加载 B+ 所在表的开始,那这时候就需要加载数据页了,因为每个表都有一个固定开始节点的记录,所以这时候就有了 表空间号+页号 的存在。 那 MySQL 因为读取数据的时候如果缓存页在 BufferPool 中的话就不用再 IO 加载了,那如何知道? BufferPool 使用 HASH 索引来记录数据页的位置,可以假想成 Java 中的 HashMap,通过一定的算法计算一定能够拿到对应的 value 值对应的槽,进入可以快速的拿到 value 值,也就是缓存的数据页 ,而 表空间号+页号 就是一个 key 值了。
4.3 BufferPool 的 LRU 管理(简单理解)
上面已经说了,MySQL 查询数据的时候,会经过一系列的操作。但是,毕竟内存中的 BufferPool 容量肯定是有限的,没有硬盘那么大,所以不可能整个硬盘的数据库数据都缓存到 BufferPool 中去。那就需要淘汰一些不常用的数据了,这就是一个简单的 LRU 原理,那就有一个 LRU链表 来管理这些数据。
LRU:链表管理数据,经常访问的数据会被放到链表头,而慢慢的,不常用的就会被排到链表后边去,发生空间不足的时候,链表尾部的数据将会被淘汰。
那接下来我们结合一下修改数据,据我们所知,修改数据是先修改 BufferPool 中的数据页,然后再在某个时刻被后台线程刷新到硬盘的。 那如果说一个查询进来,LRU 链表空间已经不足,数据页是脏页(在 flush 链表中,下说)需要刷新,但是尾部的数据页已经是一个脏页(判断存不存在 Flush链表 中),那这个查询就会被阻塞,等到脏页被同步刷新到硬盘才可以接着进行查询。 所以为什么说,全表扫描会降低数据库的运行效率,因为全表的时候需要加载很多数据到 BufferPool 中去,很当前很可能 BufferPool 空间已经不足以容纳整个页,所以需要等待链表后续的脏页被同步写入硬盘才会去查询下一页的数据。
4.4 BufferPool 的 LRU 深入管理(数据分区)
一个 LRU 链表可不是什么都没有就一条链表那么简单,MySQL 将 LRU链表 划分为 young区 和 old区。那因为我们是 JavaCoder,就简单的说成是年轻代和老年代吧!
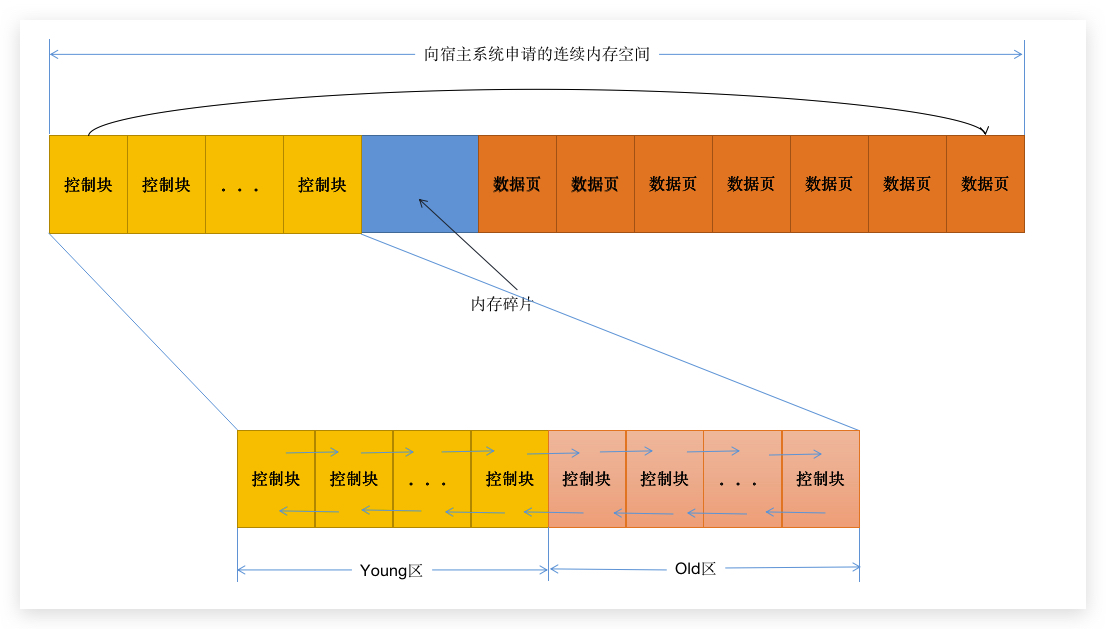
但是但是,这个新生代和老年代和 GC 的可不一样。在 MySQL 中,老年代是用来存储使用 频率不高 的数据页的(jvm 是用来存储使用频率高常年不用清除的),而年轻代是用来存储使用 频率很高 的数据页的 为啥要这么设计呢,因为有两种情况:
- 预读
- 线性预读:当访问某个区的页面超过了配置的变量的时候,会触发异步读取下一个区所有的页到
BufferPool中; - 随机预读:如果某个区
13个连续页面被读取,无论是不是顺序读取,会触发一次性加载本区所有的页,该配置默认是关闭的。
- 线性预读:当访问某个区的页面超过了配置的变量的时候,会触发异步读取下一个区所有的页到
- 全表扫描:一个全表扫描的语句会让
BufferPool中所有的数据产生一次刷新,即变成当前读取表的所有数据,而那些本应该频繁被读取的数据页就被替换掉了,然后全表后这些数据又没啥用,又要重新读取前面说的频繁的数据来放进BufferPool
OK,那上述的结构怎么解决这两个问题呢,其实很简单,就是这两个产生的数据页会先被放在了 old区域 也就是我们说的 老年代,然后,如果刚被放进去,在规定时间内被第二次访问发现少于系统参数设置的时间(后面配置会说哪个),就会将这个数据页从 old区 移动到 young区。
4.4 BufferPool 的 flush 链表
flush链表 主要是用来管理 BufferPool 中已经被修改的数据页,因为此时内存中的数据页已经发生修改,和硬盘上原有的数据页不同,所以就需要在某个时刻由 后台线程 刷新到硬盘上去。 但是,这个时候总不可能去循环所有数据页,然后判断是不是脏页吧,所以又有一条链表产生,就是 flush链表。这条链表没什么特殊的,长得和 free链表 也一样我就不画了。 那么什么时候会触发刷新脏页的机制:
- 后台线程轮询到的时候;
- 查询需要
BufferPool空间但是此时空间不足,从LRU链表的尾部刷新,判断有没有可以直接释放的,如果没有就会触发刷新的操作
五.配置多个BufferPool实例
多个 BufferPool 实例,可以提升速度,因为当有些操作需要加锁的时候,不需要加锁整个 BufferPool 而是加锁对应的实例就可以了,我们可以理解为 ConcurrentHashMap 中 分桶 的概念。
1 | [server] |
上面的配置即可将 BufferPool 分成 8 个实例。(该参数如果内存空间不足的时候,又会被程序自动修改成 1) 那每个 BufferPool 实例中都跟上面说的一样,该有的都会有。 修改 innodb_buffer_pool_chunk_size 参数可以修改每个实例运行占用的空间,默认是 128m,但是不允许在运行的时候进行修改,而是启动 MySQL 服务器的时候进行修改。在这里就需要注意一个问题,BufferPool 总大小需要算好,不然会出现一些奇奇怪怪的症状,也就是 innodb_buffer_pool_size = innodb_buffer_pool_chunk_size * innodb_buffer_pool_instances,也就是总大小 = 每个的大小 * 数量。当然如果这个等式不成立,那 MySQL 会直接使用总大小除以多少个实例的方式,来重置每个实例的空间大小。
六.BufferPool状态监控
执行语句:SHOW ENGINE INNODB STATUS\G;
1 | ..........省略其他内容 |
七. 配置BufferPool
那就统一是写配置文件的方式来配置,有些参数可以直接在运行时配置。
7.1 总大小配置
1 | [server] |
该配置是配置 BufferPool 总大小,单位是 byte,上述的配置是 3298295808 byte,那 3298295808 / 1024 / 1024 =3,145.5 m。这个是线上阿里云数据库给的配置。这个配置并不包含 控制块占用的内存空间,所以实际申请的内存空间大概是 3,145.5 m * 5% + 3,145.5 m =3,302.775m
7.2 预读配置
两个配置均可运行时配置(SET GLOBAL)
1 | innodb_read_ahead_threshold=56 # 默认配置,设置顺序访问多少页时 线性预读当前区所有页面到BufferPool |
7.3 LRU配置
两个配置均可运行时配置(SET GLOBAL)
1 | [server] |
八.完结
OK,BufferPool 的章节完结,接下来就是事务的事情了。