【聊聊MySQL】五.MySQL-子查询的过程
一.子查询
我们平时在查询数据的时候,特别是报表数据的时候,或多或少都会接触到 子查询 这个东西的吧。因为有些数据,他就是需要前套一层 子查询 来先拿到部分数据,然后再结合这部分的数据接着进行查询。
二.子查询出现的位置
子查询出现的位置,如果平时没有去总结一下的话,还真的不知道可以在这么多的地方出现。具体来说呢,好像每个地方都可以出现。
2.1 SELECT位置
比如 SELECT (SELECT * FROM business_order);,当然这个语句好像并没有什么意义。
2.2 FROM位置
有个场景,比如订单表在已经支付的时候我们需要批量的去修改其他列的数据,那么我们会写:
1 | UPDATE business_order SET status = 'DEL' |
这条语句乍一看没有问题,但是 MySQL 会给你报个错误:You can't specify target table 'student' for update in FROM clause,意思大概就是无法对查询的表进行更新。 那么我们这个需求又必须要实现咋办呢,在条件中套多一层:
1 | UPDATE business_order SET status = 'DEL' |
那么上面的 SELECT a.id FROM (SELECT id FROM business_order WHERE xxx) a 语句有另外一个子查询出现在 FROM 位置
2.3 WHERE位置
详见 FROM位置 里面的示例,WHERE id IN ( SELECT a.id FROM (SELECT id FROM business_order WHERE xxx) a); 就是一个出现在 WHERE 位置的 子查询。
2.4 其他没有意义的地方
ORDER BY GROUP BY 都是可以出现子查询的,但是并没有什么意义,就不说了。
三.子查询的分类
单独看分类这一节并没有什么意义,但因为在下面讨论查询方式的时候,需要用到这些名字。所以大概记住一个名字代表什么意思然后带着这个名字去看下面就好了。
划分维度有几个,不过我直接挑出来常用的就好了。 其实就是一个问题:跟外查询有没有关系?
3.1 有关系:相关子查询
为了有个例子,我憋着气也要写一个可以执行的带有子查询的语句:
1 | SELECT * FROM |
(我怎么会写这么无聊的代码…….. 可以看到吧,子查询 中的 scope 条件中出现了依赖外部表 student 的条件,这种查询方法就是 相关子查询。
3.2 没有关系:非相关子查询
这个简单,就是子查询直接拿到外部,还可以继续执行的语句,因为并不需要依赖外部表的值。
四.子查询执行过程
上面是关联的方式,那接下来需要根据不同的查询方式进行分类。
4.1 标量子查询
举个例子:
1 | SELECT * FROM |
就是外部表的一个列等于(或者其他 bool表达式 如 > < )另外一个子查询的时候,就是 标量子查询。
4.2 行子查询
1 | SELECT * FROM |
4.3 标量子查询和行子查询的两种不同子查询
4.3.1 不相关子查询
那标量子查询、行子查询是怎么进行不相关子查询的,其实不是很难: 就当成两个简单的查询就好了,先执行 SELECT stu_id FROM scope 然后再执行 SELECT * FROM student stu WHERE id = 上面结果集
4.3.2 相关子查询
相关子查询就比较麻烦了,需要两个表每个记录去循环,看是否同时满足外部查询和内部查询的条件,如果满足才加入结果集。 比如这个:
1 | SELECT * FROM |
会先从 student 拿出 id=1 的记录,加入成绩表的查询,看看成绩是否大于90分,如果大于90分加入结果集返回,然后再拿出 id=2 的记录。
4.4 IN子查询
4.4.1 临时表查询
IN 查询和上面两种方式不一样,因为为了防止一些问题,比如 IN ...some sql 中,后面 SQL 语句查询出来的结果集很大,可能会导致内存不足,也会因为结果集过于庞大,外部表在查询的时候无法有效的使用到索引。 所以,IN子查询 会通过一些方式,将语句转换成 内连接 的形式来进行查询。 怎么转,通过 物化表 来做,例子说:
1 | SELECT * |
首先执行子查询,即查询学生的父母姓李的所有 stu_id 数据。 那么假设,这个系统刚运行没多久,那么这个结果集(只有一列因为我们指定了查询 stu_id,并且已经去重,比如某学生的父母都姓李,那么这张临时表只会保存一个 stu_id)将会被变为一张临时表(物化成一张表)存储在内存中,并且这个表是基于 HASH索引 而存在的,然后,将 student 表与内存中的这张表进行连接,比如内存中这张物化表的名字是 student_parent_memory 那么上面这条内连接的 SQL 将进一步变成:
1 | SELECT stu.* |
再假设,系统运行的不错,一直在运行着,那么子查询的表查询出来的结果集已经超过了数据库系统设置的 tmp_table_size 和 max_heap_table_size。那么这个临时表存储的位置将发生了变化,表来是内存的基于 HASH索引 的表,现在就变成了硬盘中基于 B+树 的表而存在。 至于后续如何进行,就是上一节中说的连接基于成本来判断使用哪张表做 驱动表 以及 被驱动表 的策略了。
4.4.2 半连接
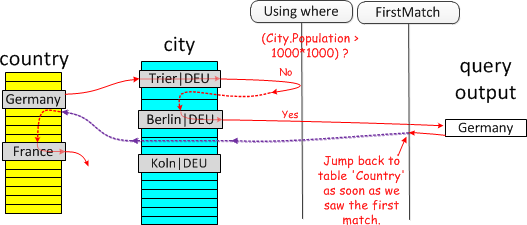
半连接可以说,为了不像上面一样创建临时表或者优化创建的临时表,然后去进行查询的一种策略。 仅适用于不相关子查询 方式一 Table Pullout 把表拉出去 如果关联查询的子查询的结果集的那个列是唯一索引,那么子查询将被跳过生成临时表的步骤,然后被拉到外面直接内连查询! 方式二 DuplicateWeedout execution strategy 消除重复值 生成一个只有一个列并且这个列 PRIMARY KEY,然后根据外部表的列来排除已经被加入到结果集的数据(因为这个列是唯一的)这种方式可以用于统计省市情况,由于满足某个条件(比如人口大于某个比率),而省可能包含很多个市,可能这个省多个市可以加入结果集,那么就可以使用这种方式来消除重复的省结果集。 方式三 LooseScan execution strategy 松散策略
1 | SELECT * |
那么在执行子查询查发货单表的时候,由于 order_id 模糊查询,而且在发货单中可能存在很多重复的记录,那么在使用发货单二级索引的时候,就可以直接跳过这些重复的订单号值,拿到不重复的值就可以了。 方式四 Semi-join Materialization execution strategy 这是上面临时表策略 方式五 FirstMatch execution strategy 匹配字表跳出字表查询 从外表取出记录去一次一次匹配字表的记录,是一种最原始的方式。如果这条记录已经满足了条件,那么假如结果集,不再去匹配子表而是回到外表,继续下一条记录。