Redis 集群部署方式
总览
使用的 Redis 版本:4 通常来说,一个小型的项目一台 redis 服务实例即可满足需求,但是当系统很大的时候,客户端读写频繁,一台机器很容易就成为性能和内存的瓶颈,这时候就需要使用集群来拓展性能了。 redis 集群有两种方式:
全量复制
redis 在复制模式下被分为两类数据库:主数据库和从数据库。一个主数据库可以拥有多个从数据库,但是一个从数据库则只能拥有一个主数据库。当主库数据发送变化时,redis 会将数据自动同步到多个从数据库中去。 在 redis 数据库中使用复制功能很简单,只需要在从数据库的配置文件中加入以下配置即可实现:
ps:以下配置是 Redis4 的配置,在以前版本需要查看配置文件的配置方式。
1 | replicaof 192.168.1.129 6379 # 配置主数据库链接信息 |
主数据库无需任何配置。 查看 redis 服务的 Replication 节点相关信息:
1 | redis-cli |
默认情况下,从数据库是只读的,如果向从数据库设置值,将会得到一个错误((error) READONLY You can't write against a read only replica.)。如果想要让从数据库可写,那么需要在配置加上以下信息:
1 | slave-read-only no |
但是即使从数据库可写,写入的数据也会被主数据库同样的键给代替了,所以一般来说,从数据库应该只是只读的模式。 这种方式主数据库只能有一个,而从数据库可以有很多个。 然而,从数据库也可以有自己的从数据库(这里应该说这个从数据库是另外一个从数据库的主数据库。
无硬盘复制
当 Redis 被配置不使用 RDB 备份的时候(删除所有的 SAVE 配置),Redis 还是会在硬盘生成 RDB 文件,这是为了在 Redis 被关闭的时候,重启 Redis 可以恢复内存中的数据。 在执行复制的时候,每次复制 Redis 都需要执行一次 RDB 文件的导出工作,这时候需要读取硬盘 IO ,必定造成复制效率的下降,在 Redis 2.8.18 开始,Redis 支持无硬盘复制操作,即在内存中生成 RDB 数据,然后通过网络传递给从服务器,避免造成硬盘性能瓶颈。 可以通过在配置文件中修改以下配置开启该功能:
1 | repl-diskless-sync yes |
增量复制
在 Redis 2.8 之前,从数据库同步主数据的都需要使用全量复制的模式,即从数据库一旦启动就会发送 SYNC 命令给主数据库,要求读取所有数据然后再写入从数据库。在 2.8 以后咧,新增了增量复制。 增量复制过程:
- 从数据库会存储主数据库的运行
id,每个实例都会有一个,每当实例重启,就会自动生成一个新的id。 - 复制过程中,主数据库一旦接收到操作命令,就会传送给从数据库,并且存入到一个挤压队列中(backlog,在我看来有点像
MySQL的binlog文档),并记录当前挤压队列中的命令的偏移量范围。 - 同时从数据库接收到主数据库的命令的时候,也会记录下数据的偏移量。
从数据库一旦断开,重新连接上主数据库的时候,不再发送 SYNC 命令,而是 PSYNC 。格式为 PSYNC 断开连接前的命令偏移量 。主数据库收到请求将会查看是否可以发送偏移量后面的内容给从数据库。
- 首先主数据库拿到了运行ID和偏移量,会判断运行ID是否和自己目前的相同,如果不同即进行全量复制。
- 判断命令偏移量是否存储在当前的积压队列里边,如果存在,进行增量复制,如果不存在,即进行全量复制。
主数据的挤压队列默认是 1m,可以通过配置修改:
1 | repl-backlog-size 10m # 积压队列长度 |
积压队列长度应按照网络情况,机器情况设定,积压队列越大,可容忍的断连时间就越长。
哨兵模式
准备复制主从数据库
在复制模式下,我们项目可以通过读写分离来提高系统并发量。但是当主数据宕机的时候,需要人工手动切换主从数据库,比较繁琐。如果引入哨兵模式,哨兵就会自动的帮我们完成上面的动作。 在系统中,我们只需要运行一个哨兵,通过配置主数据库的连接信息。哨兵即会向主数据库发送一条 INFO replication 命令,了解当前系统中有多少个从数据库。从而各自读取从数据库的信息,并且建立与从数据沟通的链接。 OK,我现在准备了三个虚拟机:192.168.1.129(Master) 192.168.1.134(Slave1) 192.168.1.139(Slave2) 关闭防火墙,配置 129 机器为主 Redis 数据库。 先测试正常的复制用法。
配置哨兵
哨兵完全配置在 redis路径/sentinel.conf。 当前我们需要配置他监控主数据库,并且配置主数据库的密码(这不要忘记了,我忘记了所以总是认为掉线了)。修改连接的主数据库地址和连接密码:
1 | # 主库名字 主库IP 端口 多少票通过认为数据库掉线,用于多个哨兵的时候配置 |
然后运行启动哨兵:
1 | redis-sentinel sentinel.conf |
运行启动配置文件会被覆写新增从库的监控地址。 来到这里表示哨兵已经就位,开始看看哪个屌毛偷懒了。
划重点的配置
哨兵和 Redis 中的通讯会受到 bind 配置和 protect-mode 的影响。如果配置这两个的话,哨兵的配置也需要加上相关的配置,如果没有配置的话,那么需要关闭哨兵的 bind 和 protect-mode 配置!我在测试的时候卡在这里很久。 OK,因为是自己使用的,先关闭掉这两个配置先。
测试哨兵
分别把服务都启动起来,包括哨兵。即可看见,上面的 Redis 132库 是 Master 角色,下面两个 133 和 134 是从库。 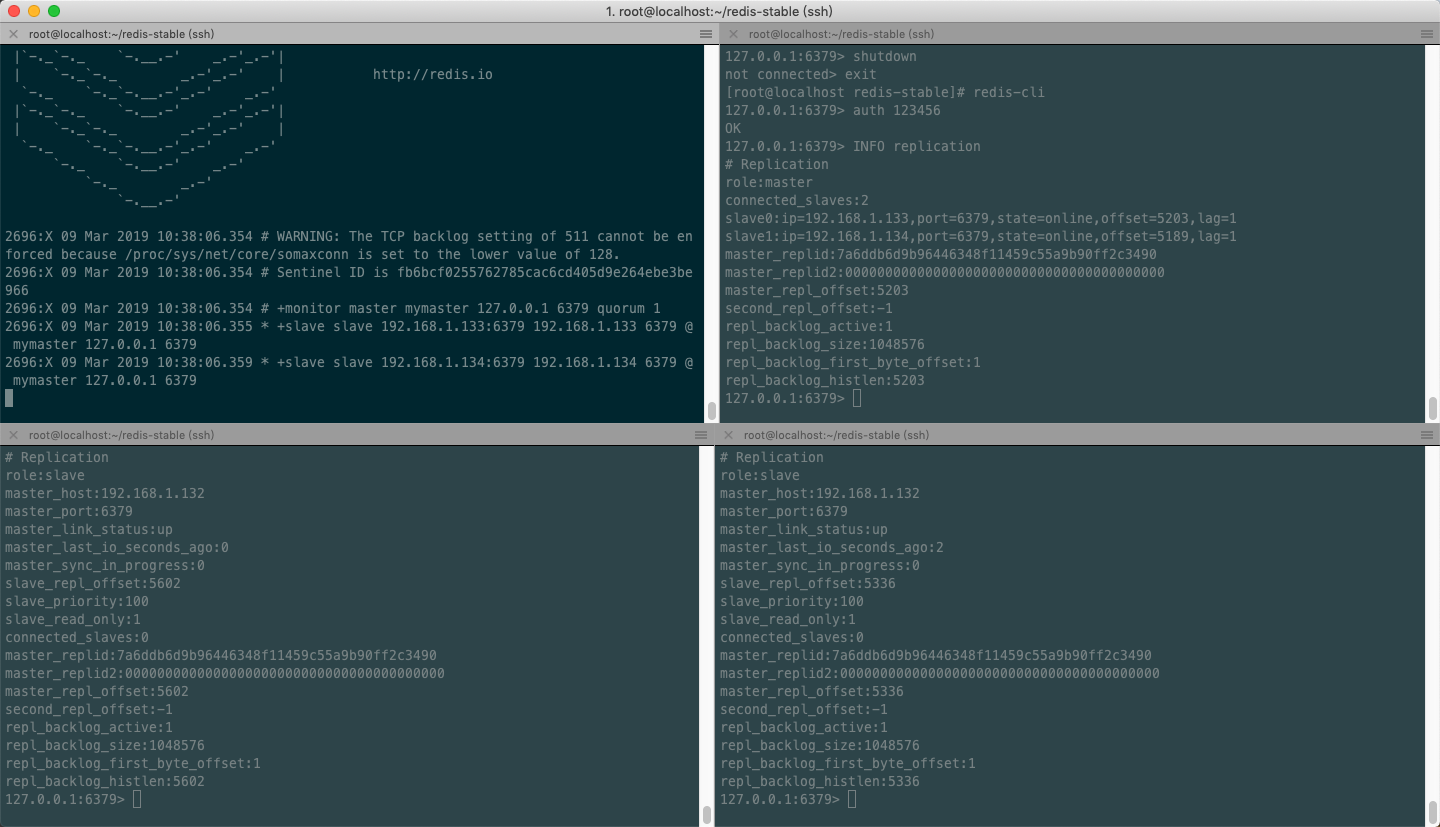
现在我进入主库服务器,把主库 kill 掉:

可见干掉主库进程的时候,哨兵开始进行投票选举,然后选出来了 127.0.0.1 作为主库(因为哨兵就运行在这台机器上面)然后,哨兵开始切换所有数据库的状态的时候,也会把当前宕机的加入,但是是以从数据库的身份加入的,所以可以看到有 +sdown 输出
集群模式
即使我们使用了哨兵模式保证了 Redis 多实例的运行,但是因为是使用复制原理来做的,所以我们的 Redis 存储量极可能会受到最小机器的存储量的影响,形成木桶效应(也就是整个集群能存储多少数据取决于最小配置的实例) 在我们应用还不会很大,数据量不会很多的时候,哨兵模式完全够用(据我所知我们现在商城存储量才 200m 多点) 虽然我在项目中可能完全不需要 Redis 的集群配置,但是为了丰富文档,我还是决定写一写。 早期 Redis 不支持集群的时候,我们一般的做法是使用客户端来做的集群。比如 Java 客户端的 Shardis 。通过一定的规则计算出 Key 应该存储在哪个节点,从而写入数据库,读取也一样。但是这种做法有个弊端,就是后期的拓展性很差,当需要新增数据库的时候,我们所有的数据都会从新被计算,从而导致新增节点需要重置所有数据的尴尬局面。 当然现在 Redis 的集群也有一定的缺陷,当想读取多个键的时候,如果多个键均分布在同一个节点的时候可以正常读取,但是当键落在不同节点的时,此时 Redis 将会报错。
配置集群
配置集群必要点:
- 每个实例配置中的
cluster-enabled均需要为yes,也就是每个实例都要打开集群模式; - 集群中必须存在 3 个主数据库,集群才能正常启动。
OK,为了更好玩一点我就不使用单机形式启动,而是启动 6 台虚拟机进行模拟。 第一步 修改配置文件
1 | # 开启集群模式 |
第二步 启动所有 Redis 实例,每台实例都会打印以下日志表明身份
1 | 11837:M 14 Mar 2019 03:06:48.465 * Node configuration loaded, I'm 15876fe78b4d5bd61f8df8bdc748d5358a761ef0 |
第三步 使用 redis-cli 连接所有的实例
1 | redis-cli --cluster create 192.168.1.143:6379 192.168.1.144:6379 192.168.1.145:6379 192.168.1.150:6379 192.168.1.151:6379 192.168.1.153:6379 --cluster-replicas 1 |
就可以看到输出了:
1 | 11956:M 14 Mar 2019 07:03:17.632 * Replica 192.168.1.150:6379 asks for synchronization |
这个表示 150 服务器是主服务器,当前服务器是从服务器。 测试数据:
1 | # 需要使用 -c 参数表示读写集群中的 redis |
集群常用命令
1 | 127.0.0.1:6379> CLUSTER NODES |
CLUSTER NODES 可以查看当前集群中插槽的情况以及主从的情况。
插槽
一个 redis 共拥有 16384 个插槽,将会平均分配给每个主数据库,像上面的命令后面的 connected 5461-10922 即表示这个主数据库处理哪部分的插槽。 每个键将会落在哪个插槽,redis 会通过建的有效部分(如果存在 {} 则取 {} 中间的至少一个字符,如果不存在,整个键都是有效部分)进行 CRC16 算法计算出来散列值,然后与 16384 进行取余,然后得出来落在哪个节点的哪个插槽上去。 使用 {} 指定有效部分可以使相似业务的键值落在同一个节点,比如 {order}:details {order}:info 这样既可使这两个订单业务的数据落在同一个节点上去,从而支持一些集群不支持的命令。
故障恢复
- 集群中每个节点都会定时向其他节点发送
ping命令,并且判断哪个节点没有回复 - 将没有回复的节点通知其他节点试试看能不能
ping通 - 如果半数以上的节点认为已经下线,则集群系统会标记这个节点已经掉线了
- 如果挂掉的节点是个
master并且拥有slave节点那么他的slave会通过选举自己,然后由集群进行投票,从而竞选升级为master(这里可能会因为总是没有合适的slave而出现集群短时间不提供服务) - 如果有半数以上的
master挂掉了,那么集群将不会再对外提供服务 -
master挂掉以后可以重新加入集群,但是slave挂掉以后如果master不同了,需要通过修改配置文件来加入集群。