【聊聊MySQL】十一.MySQL-InnoDB的数据库事务锁
一.InnoDB锁
并发的世界里,就离不开锁这个东西,即使会降低一些执行效率,但是该锁住的还是得锁住。MySQL 也一样,当两个 会话 同时修改一条数据的时候,就需要通过锁机制来保证修改后数据的正确性。锁听起来很牛逼,但是简单的概括一下也就是对某个资源(一个变量)的修改操作撸成一条队列来执行,由于执行之前需要判断一些锁的信息,所以执行效率肯定是要低一点的。
不过由于学 Java 的,这个鬼东西也可以结合起来一起说说,反正原理都一样。
通常来说,对一个资源的操作会出现以下几个情况:
读读:不会对资源产生副作用,所以不需要加锁;写写:两个线程想要动手修改同一个资源,那不用说肯定先到先写;读写:一个读一个写的线程,那也是谁先到达现场,谁先锁定。
1.1 写写
假设两个线程都要对同一个记录进行操作,那么就会产生锁的竞争了:
首先 线程A 先到达数据行现场:

接下来,线程B 说我也要更新:
但是发现 线程A 在做操作,这时候只能干巴巴的先等着,不过为了性能,会把线程给睡眠了(类似于 await())
然后,线程A 做完了,提起裤子准备要走,这时候就跟 线程B 说,轮到你了:

1.2 读和写
一个 读线程 和一个 写线程,为了防止 脏读 不可重复读 等一些事务可能出现的问题,我们前边说过 InnoDB 使用 MVCC 来控制读取的东西,而另外一边,写线程 可以继续写的操作。
但是,业务经理 说,我就要读取的事务完成,才可以进行操作(例如银行这种比较高要求一致性的系统),那么 读 就需要用到锁了:
1 | SELECT * FROM table WHERE id = 1 FOR UPDATE; // 排他锁 |
上面这句执行后,事务的执行模型 就会变成上面 写写 一样的形式了。
很多时候,使用 MVCC 更加的高效,不过如果业务是很高度准确性要求的话,就需要用到这种方式。
二.锁的类型
2.1 行级锁
这个和 ReentrantReadWriteLock 可以相关联理解:
排他锁:Shared Locks,一般简称S锁,两个操作的排他锁不会阻塞,但是跟下面的排他锁使用的话,就会阻塞,等下说;独占锁:Exclusive Locks,一般简称X锁,如果发生修改锁定的时候,使用的锁都是排他锁。
那么 排他锁 就是 ReentrantReadWriteLock 的 readLock(),而 排他锁 就是 writeLock() 了。
画个表看看兼容程度:
| 兼容性 | X |
S |
|---|---|---|
X |
不兼容 |
不兼容 |
S |
不兼容 |
兼容 |
那么只需要记住一个 S锁和S锁是兼容的 就可以了。
2.2 表级锁
表级锁也有 S锁 和 X锁,兼容程度也和 行级锁 一致。不过如果一张表有 锁,此时如果需要对表中的某一行做操作,需要判断 表级锁 和将要加的 行级锁 是否兼容,不兼容就需要阻塞。反过来如果想要对表加 表级锁,同样也需要此时表中数据的 行级锁 和 表级锁 是否兼容。
所以有这样一个需求,当我需要对一张表加锁的时候,怎么知道这张表是否有 行级锁?简单想想的话,就是遍历这张表的所有记录了,但是我们生产一张表动不动就上千万个数据,遍历效率实在太低了,而且还要考虑遍历的时候需要对其他事务进行阻塞。所以,InnoDB 为了解决这个问题,又有一种锁 意向锁(Intention Locks):
可以理解成一个标记,当需要对表中某条记录加 S锁 时,会先在 表 上挂一个 Intention Shared Locks,简称 IS锁,而当需要对表中某条记录加 X锁 时,则相对应的在 表 上挂一个 Intention Exclusive Lock,简称 IX锁。
而这两个锁,并没有相对应的 锁逻辑,只是为了快速判断一个 数据表 中,是否有 S锁 或者 X锁 记录而已,规避需要加 表锁 的时候,不得不循环遍历所有数据的低效。所以 表级锁 的兼容性如下:
| 兼容性 | X |
IX |
S |
IS |
|---|---|---|---|---|
X |
不兼容 |
不兼容 |
不兼容 |
不兼容 |
IX |
不兼容 |
兼容 |
不兼容 |
兼容 |
S |
不兼容 |
不兼容 |
兼容 |
兼容 |
IS |
不兼容 |
兼容 |
兼容 |
兼容 |
那什么时候会发生表级锁,当然就是修改 数据表 结构的时候啦,或者在数据库崩溃的时候,恢复数据的时候会用一下 表级锁。
2.3 特殊的锁–AUTO-INC锁
当我们一个表的主键设置是 数据库自增 的时候,插入一条数据就需要为 自增变量 加锁,这个就是 AUTO-INC锁。
而 AUTO-INC锁 也有不同的类型,可以通过 innodb_autoinc_lock_mode 来控制不同的类型:
innodb_autoinc_lock_mode = 0:执行插入语句的时候,在表级加一个AUTO-INC锁,为插入的数据分配递增的值,语句执行完毕即释放AUTO-INC锁,如果插入语句遇到其他事务在使用这个锁的时候,就需要阻塞等待所释放;innodb_autoinc_lock_mode = 1:1和3两种方式混合使用,当确定插入数据的数量的时候使用AUTO-INC锁,不确定插入数量的时候(比如INSERT...SELECT等)使用轻量级锁。innodb_autoinc_lock_mode = 2:使用一个轻量级的锁,生成本次插入需要用到的所有值之后,释放锁,并不需要等待插入语句执行完成才释放。
三.深入行级锁
那么行级锁只是简单的对一个数据行加锁吗,肯定不是的,因为需求总是那么多变,可能需要对范围加锁,可能需要对新插入的数据加锁等等的需求,所以行级锁下,又有一些分类:
3.1 Record Locks
这个 Record Locks,就是真正意义上的行级锁了,意为锁住一条真正的数据。我们知道,InnoDB 把数据存储在一颗 B+ 树上,称为 聚簇索引, Record Locks 就是加载 聚簇索引 上记录的一个锁:
- 当一条记录有
S锁,那么其他事务可以继续获取S锁,而不可以获取X锁; - 当一条记录有
X锁,其他事务无论想获取什么类型的锁,都需要阻塞等待。
我们知道一个数据页长这样子的:
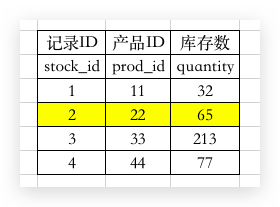
不过为了简单点:
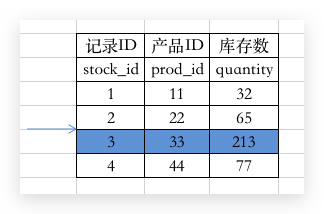
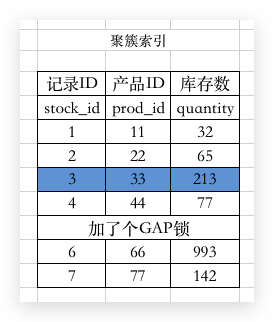
那比如说,我现在要操作 prod_id=22 的库存,需要加上一个 X锁:
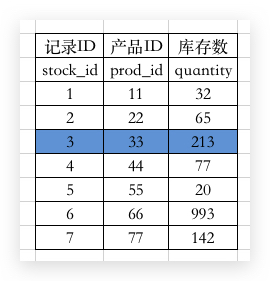
那么其他加锁的操作都会被阻塞。
3.2 GAP锁
GAP锁 是为了防止 幻影记录 而诞生的,我们知道 REPEATABLE READ 级别的隔离下,幻读是可以通过 MVCC 解决的,但是如果需要通过加锁的方式解决,就有个问题,不知道加哪个记录。
所以,我们就需要对数据页中的某个数据(边界)加上一个 GAP锁:
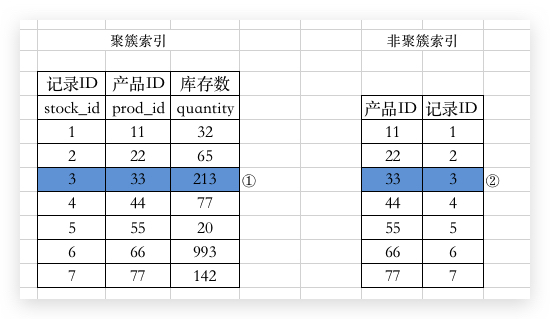
在这里,比方说查询库存小于 200 的 prod_id 集合,使用加锁的形式:
1 | SELECT * FROM stock_info WHERE quantity < 200 LOCK IN SHARE MODE; |
那么这个 GAP锁 就会被加在 stock_id = 3 的前面,这时候如果插入一条数据 INSERT INTO stock_info values(null, 55, 200);那么这条插入语句将会被阻塞。
那如果想要锁住最小值或者最大值怎么办,别忘了一个数据页中有两个特殊的列:Infimum 和 Supremum。把这两个锁了是不是就完事了。
3.3 Next-Key Locks:
如果想要锁住记录并且也锁住间隙怎么办,就可以使用 Next-Key Locks。他是 Record Locks + GAP锁 的合体,锁住的那条记录即不允许在他前后插入数据,也不允许修改这条 数据行 的数据。
3.4 Insert Intention Locks 插入意向锁
那么在插入数据的时候,需要判断插入的位置是不是被 GAP锁 锁住了,如果有的话就需要阻塞当前事务,等待 GAP锁 的释放。那么 InnoDB 的大佬也规定,如果插入数据的时候进入阻塞状态,也需要生成一个 Insert Intention Locks 插入意向锁 挂在这条记录上边,表明在这个间隙目前有数据想要插入。
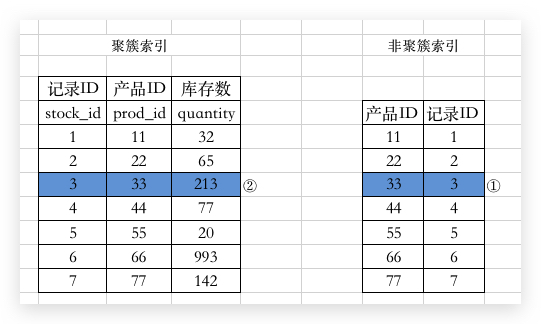
注意:意向锁并不会因为前边有个 GAP 锁就等待,而是直接锁住,再进入等待。事实上他也不介意其他锁进来。
3.5 隐形的锁
那么如果一个事务首先插入一条数据,然后另外一个事务马上用到 SELECT ... FOR UPDATE 或者 SELECT ... LOCK IN SHARE MODE 想要读取这条数据咋办,亦或者想要修改这条数据,如果这两种情况都允许的话,那么就会出现 脏读 和 脏写 的问题了。
所以一个隐形的锁横空出世:trx_id(掀桌子):
- 对于
聚簇索引,该记录的trx_id表示当前事务ID,如果当前事务想要给这一行加锁的时候,就会查看这个trx_id的事务在当前是否是活跃状态,如果是的话,就舔狗般的帮他创建一个锁(锁有个属性是isWaiting=false)然后自己创建一个isWaiting=true的锁,然后进入等待状态; - 对于
非聚簇索引来说,因为没有trx_id隐藏列,不过非聚簇索引数据页的PageHeader有个PAGE_MAX_TRX_ID列,表示对这个页面做过改动的最大事务ID,如果这个值小于当前活跃的事务ID,那说明对这个页面修改的事务都已经提交了,否则就需要定位到记录,回表重复上面一步的流程。
四.锁结构
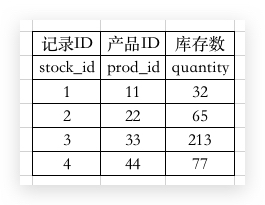
加锁,那肯定是有事务对 数据行 发生了修改,所以就需要第一个属性记录必要的锁信息。
然后数据行都在 索引树 中,所以我们需要一些索引信息
第三个,表锁 就需要记录 数据表 的一些信息,而 行锁 就需要记录 数据行 的信息
type_mode 则是记录锁的类型,比如 IS锁 或者 IX锁 啊等等信息,也记录了是 表锁 还是 行锁,而上面也说了 GAP锁 等类型,也记录在这里(注意,和 IS锁 的类型记录不在同一个地方)这个字段是由一堆 比特位 组成的,而这个锁是否在等待 is_waiting 也记录在这里(一般第一个加上的锁不需要等待,所以这个值是 false,后面进来的锁都是 true)
而类型的最后一个 比特位 则存储了数据的信息,包括 最大值 或者 最小值。
摊开说有点复杂也不需要记住,只要记住锁记录了上面的信息就可以了,所以我偷懒不说,等需要用到的时候再聊。
五.手动分割线
上面说的都是 数据库锁 的一些结构,下面就要说 SQL 的加锁情况了。
六.SELECT语句加锁
前面隔离级别和 MVCC 的时候也说过 SELECT 在不同的隔离级别下查询出来以及发生的问题是不同的:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
READ UNCOMMITTED:读未提交的 |
√ | √ | √ |
READ COMMITTED:读已提交的 |
× | √ | √ |
REPEATABLE READ:可重复读 |
× | × | √ |
SERIALIZABLE:串行化 |
× | × | × |
那么咋整呢,可以使用 MVCC 的方式来避免这些问题,但是为什么使用 MVCC 是因为它能够满足大部分的业务需求,并且执行效率要比 加锁 高很多,所以很多时候,我们 SQL 执行的时候使用的避免问题的方式都是 MVCC。
但是有时候我们的业务背景要求,一点错误或者小插曲都不能出现,这时候就需要对我们读取或者操作的数据进行 加锁 执行了。
而 加锁 加什么锁 则不是必然的,因为 加锁 这个操作涉及到了很多客观元素,比方说 隔离级别 啊,使用什么索引啊 查询条件 等等。
那首先,建个 产品库存表stock_info 来做示例吧:
1 | -- 一个库存表 |
1 | SELECT * FROM stock_info; |
6.1 普通读
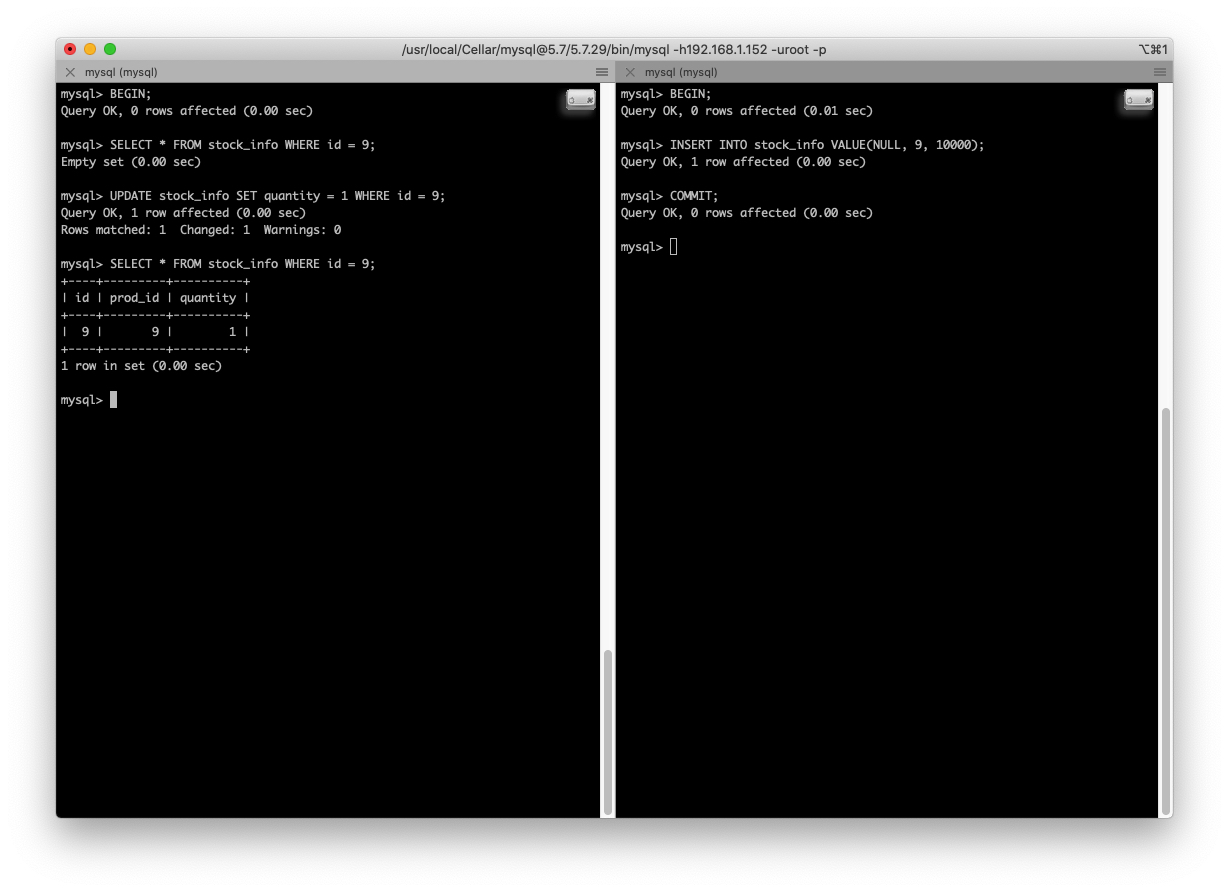
我们使用 MySQL 默认的隔离级别是 REPEATABLE READ,前面说过,解决了 脏读,不可重复读 和 幻读 的问题。但是吧:
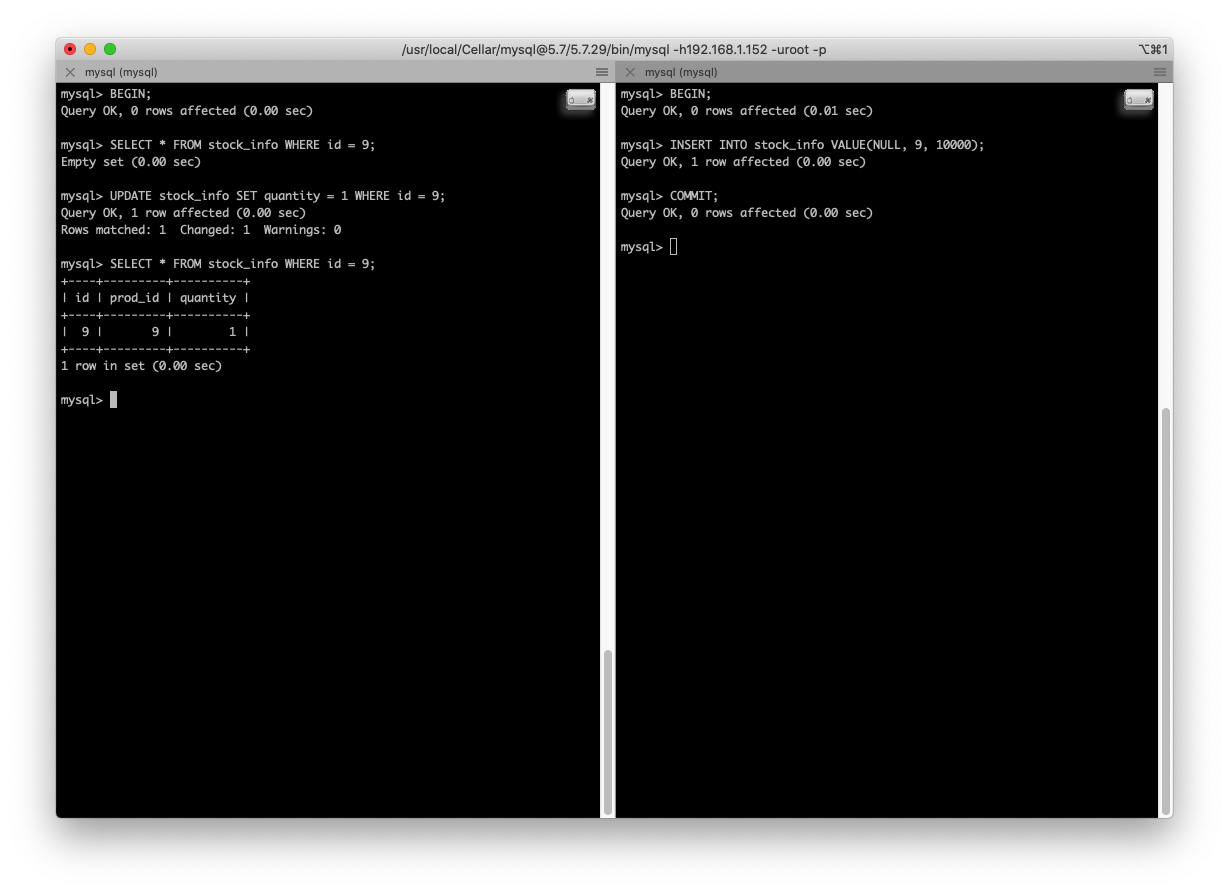
左边 事务A 第一次查询 id = 9 的数据,是空的,但是由于右边的 事务B 插入了 id = 9 的数据并 提交,事务A 又更新了 id = 9 的数据(所以此时 数据行 的 trx_id 列又变成了 事务A 的 id,又因为执行了 UPDATE 语句,所以 ReadView 被刷新了),并且读取,就可以返回数据啦。
所以,REPEATABLE READ 可以说并没有完完全全的解决 幻读 的问题。
那么怎么解决上面的问题,那就剩下 加锁 的方式了。
锁定读的语句:
SELECT ... LOCK IN SHARE MODE;SELECT ... FOR UPDATE;UPDATE ...;DELETE ...;
因为后面两种情况需要先读取 数据行,所以也属于 锁定读 的语句。
因为 READ UNCOMMITTED 和 READ COMMITTED 的加锁方式是一样的,所以,一起说就好了。
6.xxxxx 分割线,以下属于 READ UNCOMMITTED/READ COMMITTED 加锁方式
6.2 等值锁定读
针对 SELECT 语句,锁一般加在 聚簇索引 的数据行上面。比方说下面两个语句:
1 | -- S锁 |
一个加 S锁,一个加 X锁:
那么这条数据行就被加锁了。
而如果我更新这条数据:
1 | UPDATE stock_info SET quantity = 200 WHERE id = 3; |
如果这条数据没有索引,那加锁的状态和 SELECT * FROM stock_info WHERE id = 3 FOR UPDATE; 是一致的,就不再画出来了。
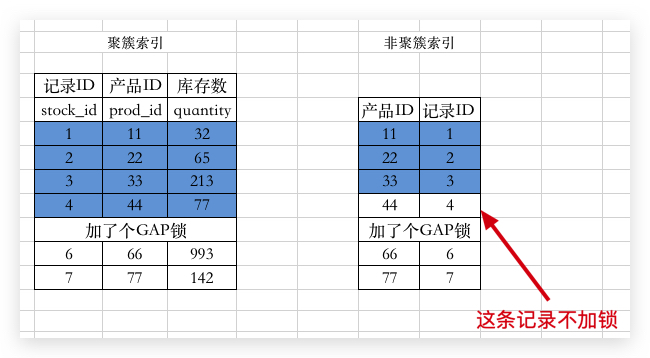
而如果更新的列是有 二级索引 的话,那么两步走:
- 先在
聚簇索引上为这条记录加上锁; - 再在
二级索引上为对应的索引加锁。
比如:
1 | UPDATE stock_info SET prod_id = 99 WHERE id = 3; |
而如果查询条件是先从 二级索引 出来的话,比如 UPDATE stock_info SET prod_id = 99 WHERE prod_id = 33;,那加锁顺序又要反过来:
而如果,同时有两个事务,一个 UPDATE stock_info SET prod_id = 99 WHERE id = 3; 另外一个 UPDATE stock_info SET prod_id = 99 WHERE prod_id = 33;,那么:
就 死锁 了,因为 左事务 先 加锁 了 聚簇索引,后 加锁二级索引,而 右事务 的 加锁顺序 反而是反过来的,这就导致了,左事务 在等待 右事务 释放 二级索引锁,而 右事务 在等待 左事务 释放 聚簇索引锁。所以导致死锁的发生。
UPDATE 和 DELETE 是一样的,所以记住一个结论:
如果使用了索引加锁,则先加二级索引的锁再加聚簇索引的锁,如果使用了聚簇索引则先加聚簇索引的锁再加二级索引的锁。就是谁先到达先加谁的!
6.3 范围锁定读
那按照顺序,依然先看看走 聚簇索引 的流程:
1 | SELECT * FROM stock_info WHERE id < 5; |
这个看起来有点简单,无非就是把上面等值的所有列加锁就行了呗,其实 不是的,他是这样子走的:
- 先拿到满足条件的第一条记录,也就是
id = 1的记录,然后加锁; - 判断是否符合
索引条件下推的条件,索引条件下推是为了减少回表次数,也就是减少IO次数,才会发生索引条件下推的现象,而索引条件下推主要用于二级索引,所以这里并不需要判断; - 判断是否符合
范围查询的边界条件,因为id = 1 < 5所以返回给server层继续处理,又因为聚簇索引是一个有序的树,所以到了id = 5的时候,会释放掉当前循环到的数据行的锁,然后告诉server层已经查询完毕; server层继续判断,上一步中如果已经到达边界的话,会收到查询完毕的信号,返回数据给客户端。那如果没有收到查询完毕的信号的话,就需要继续重新判断数据有没有满足id = 1 < 5这个条件(第二次判断,因为没有满足索引条件下推的条件,所以这一层又要判断一次),如果符合就加入到发送给客户端数据的结果集里边,如果不符合,要释放数据行的锁;- 拿当前
数据行的下一条数据的指针,走到第二条数据,重复以上步骤,直到第4步查询结束为止。
按照我们循环的习惯来说,id < 5 还会走一下 id = 5 的数据进行判断,所以这条 数据行 会在 第1步 到 第3步 被短暂加一下 锁。
所以,又双叒叕可能会出现 死锁 锁竞争 等问题。
而如果条件是 id > 5 呢,首先拿到第一条数据也就是 id = 6 走走走走到了 Supremum 记录的时候,就不会再继续加锁了,直接返回给 server层 处理。
那如果是修改到了 索引数据 ,亦或者先通过 索引 找到需要加锁的记录呢,那就跟上面 等值查询 的索引加锁方式一样了,先遍历到的,就先加锁。
所以 UPDATE stock_info SET prod_id = xxx WHERE id < 5,就是先找到 id = 1 的进行加锁,然后去索引再加锁,然后 id = 2、id = 3 依次循环下去。
而 UPDATE stock_info SET prod_id = xxx WHERE prod_id < 55 则加锁顺序相反,其他一样。
依然记得 最后一条边界记录要锁一下。
6.4 全表扫描读
1 | SELECT * FROM stock_info FOR UPDATE WHERE quantity > 100; |
这个加锁就简单粗暴了,每一条数据循环一次,然后在 server层 判断一下(因为没有 条件下推),满足即加入结果集,不满足则 释放锁。
6.xxxxx 分割线,以下属于 REPEATABLE READ 加锁方式
加锁之前,在 6.1 普通读 节说到的例子,REPEATABLE READ 可能还是会出现 幻读 的问题。REPEATABLE READ 加锁的方式则会比上面两种隔离级别要多样化,所以 幻读 问题也顺带解决了。
6.5 等值锁定读
如果查询的记录存在:SELECT * FROM stock_info WHERE id = 5 FOR UPDATE,那么加锁的形式跟之前是一样的,这里就不再重复。
那如果记录不存在的话比如:
1 | BEGIN; |
那么前面说了那么多的 GAP锁 就来了:

也就是说在 (4, 6) 区间范围内,有个 GAP锁,那其他事务想要把数据插入到这里的话,就要等我 COMMIT 事务以后才能够插入,也就可以防止上面 6.1 普通读 节说到的 幻读 问题。
而如果用到了 二级索引 比方说 SELECT * FROM stock_info WHERE prod_id = 55 FOR UPDATE 的话,那二级索引对应的节点也会跟 聚簇索引 一样,加上 GAP锁。先后顺序也是取决于先到 二级索引 还是先到 聚簇索引:
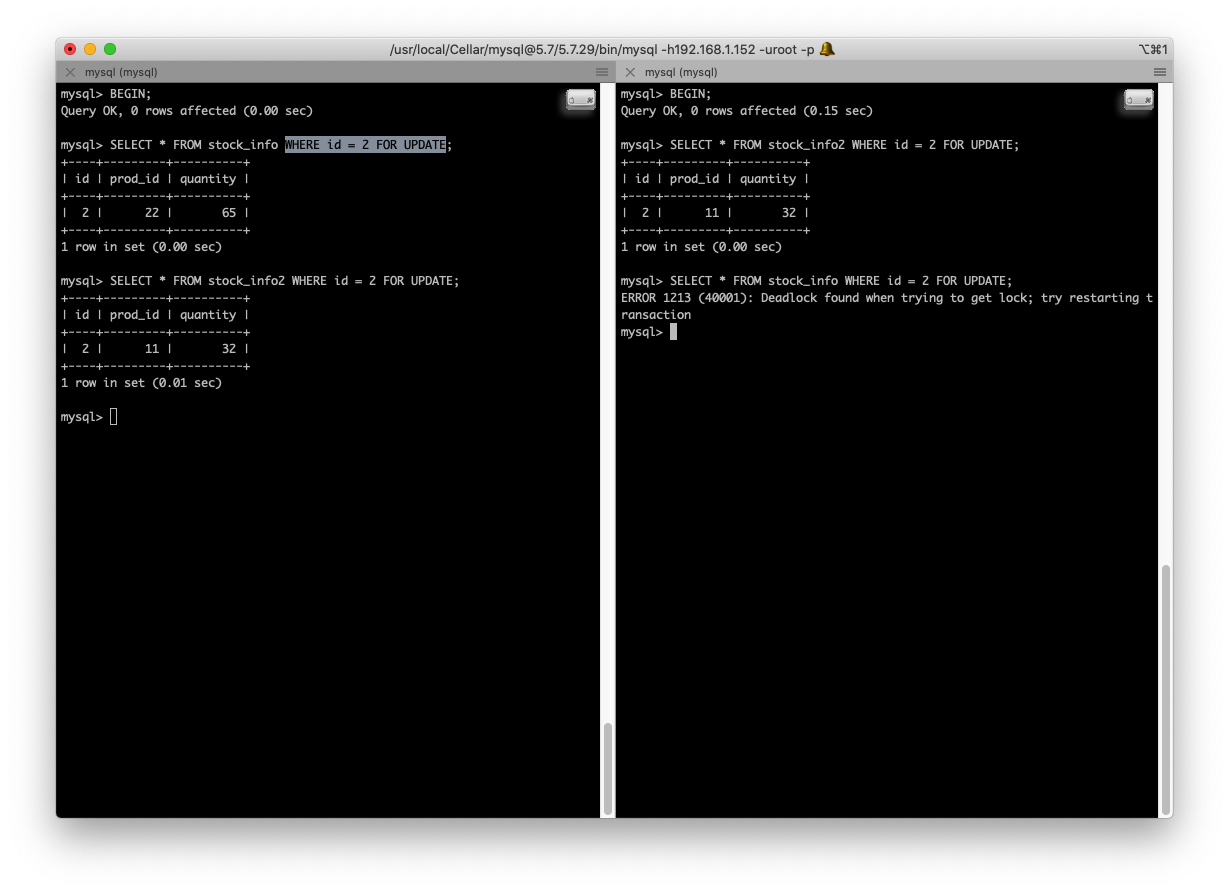
这里还有一点主意的是,如果 这个二级索引是一个唯一索引,那么 聚簇索引 上的数据就不需要加锁了,因为 二级索引 的列是 唯一的,锁住那一个数据也就可以防止插入数据了。
6.6 范围锁定读
上面 READ UNCOMMITTED/READ COMMITTED 我们说,会为满足条件的 数据行 都加上锁,那么在这里为了防止 幻读,所以还要再加上一个锁:next-key锁。因为既要防止 数据行 被修改,也要防止在空隙里面被插入数据。
比方说 SELECT * FROM stock_info WHERE id < 4,我们说了 READ UNCOMMITTED/READ COMMITTED 中 id = 4 加了一下锁,又会释放掉,但是在 REPEATABLE READ下,他是不会释放的,并且还加上了 3 到 4 之间的 Next-Key 锁。
而如果此时,我对 id < 4 的数据都更新了 prod_id 的列,因为此时使用的是 聚簇索引,所以 二级索引 上 id = 4 的列不会被加锁。
那加锁顺序,肯定就是先 聚簇 再二级 了。
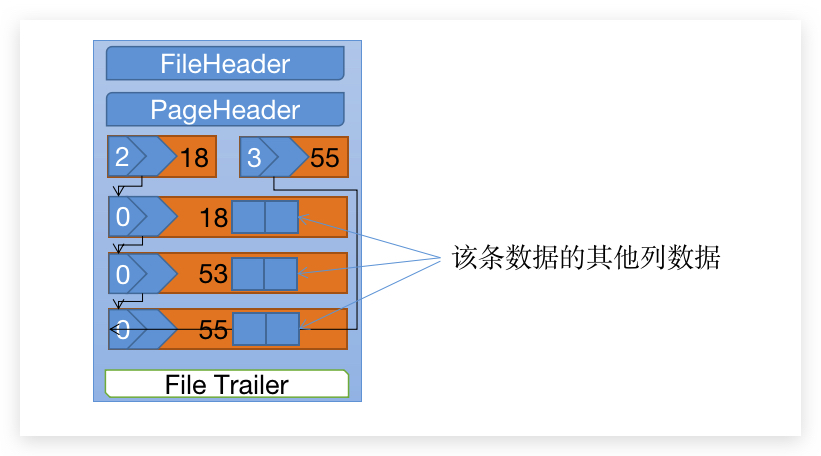
而如果我们的范围查询发生在 二级索引 上面的话,取而代之的是 二级索引 上的每条记录都会被加 Next-key锁,聚簇 上的数据不加 GAP锁。
因为需要放置修改 二级索引 以及在 二级索引 间隙插入数据,所以 锁 发生在 二级索引 上,不画图了。
6.7 全表扫描
1 | SELECT * FROM stock_info FOR UPDATE WHERE quantity > 100; |
依然使用这条 SQL 查询,因为每读取一个记录就会给这个记录加上 Next-Key锁,返回 server层,判断满足条件则返回给客户端。而如果发生全表扫描并且加了 锁,因为 REPEATABLE READ 不会释放锁,所以,发生这种情况的时候,整个表都被锁住了!!!。那其他的 事务 对这个表操作的时候均会被 阻塞。
七.INSERT的情况
INSERT 语句插入的时候,如果遇到上一条记录加了 NextKey锁 的话,那么会在该记录上加一个 插入意向锁,并且 事务 进入 阻塞 状态。
而如果插入的时候遇见一些状况,也会 加锁:
- 遇到重复值的时候,如果说在插入
聚簇索引或者唯一二级索引的时候,发现INSERT语句中某个值冲突了(也就是说存在了索引中了),那么会对造成冲突的数据行加锁:READ UNCOMMITTED/READ COMMITTED加S型行锁;REPEATABLE READ/SERIALIZABLE加S型Next-Key锁;唯一二级索引统一加上Next-Key锁。
- 如果使用的是
INSERT...ON DUPLICATE KEY语法,会在原来冲突的数据行上更新,所以,加什么锁肯定就一目了然了吧; - 如果插入的数据带有
外键检查,那么关联到的数据行会被加上S行锁,而如果查找不到外键记录,则外键记录的空白位置在REPEATABLE READ/SERIALIZABLE会被加上GAP锁,其他隔离级别则不会加锁。
七.死锁
似乎所有程序聊到 锁 的问题,就会有 死锁 的问题:
7.1 普通资源锁
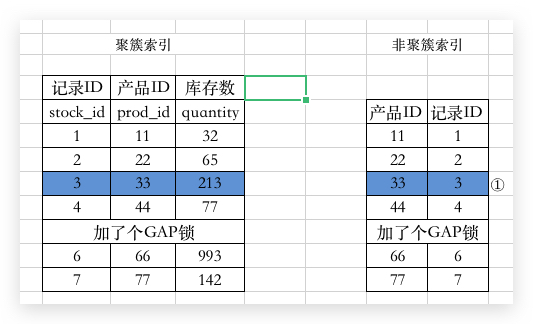
当两个 事务 锁住的数据需要相互等待的时候,就会出现这种 死锁 的情况。
7.2 插入GAP锁
是这样子的:
| T1 | T2 |
|---|---|
| begin; | begin; |
| delete from ta where a = 4; | |
| delete from ta where a = 4; | |
| insert into ta(a,b,c) values(4, 11, 3),(4, 2, 5); | |
| insert into ta(a,b,c) values(4, 11, 3),(4, 2, 5);// 出现死锁 |
这大概就是 T1 和 T2 两个执行了 DELETE 的时候都持有了 GAP锁,两个插入,T1 在等 T2 的 GAP锁 释放,T2 在等 T1 的 插入意向锁 释放,所以 死锁 了。
7.3 更新索引锁
这个在上面的 6.2 等值锁定读 已经说过,不在重复了。