【聊聊MySQL】九.MySQL-InnoDB的数据库事务的执行之UNDO_LOG
一.UNDO LOG
之前说了数据库最重要的是持久化,那现在就需要来说 原子性 和 隔离性 了。实现这两个目标最重要的的元素就是 undo log。 在日常开发中,我们也有 回滚 数据的需求。比方说,插入的某条数据不符合数据库的长度要求,就会抛出异常,从而触发 Spring框架事务 发送一个 ROLLBACK 命令给数据库,数据库就会把前面做的修改给重新还原回来。所以也需要 undo log。undo 在中文不知道叫什么比较容易理解,后文就直接用这个英文名称吧。
二.想象中的回滚
我们任何一次对数据库的改动,都会把就的数据信息记录起来,当遇到 ROLLBACK 指令的时候,就把记录起来的数据覆盖到目前的数据上就好了。比如新增,就删除掉,更新,就把它写成以前的数据,如果是删除,那就把记录重新放回去吧。好像蛮简单的,不过计算机可不同生活日常,需要考虑的东西有很多,考虑 并发性 呀,还有 是否其他人可见 啊等等这些资源共享问题。那为了提速,就需要一连串的操作来管理这些数据了,不仅仅有 undo log,还有 数据库锁。那接下来就来了解怎么实现这个功能的。
三.找到对应的事务
为了能够管理不同 事务 的 undo log,所以起码我们需要先知道这段日志对应的是哪个 事务 的吧,所以就有了 事务ID 这个东东。 那么在开启一个 事务 的后,第一次对数据库中的表进行操作的时候,就会生成一个 事务ID,同样他也是一个全局变量,每当分配一次就会自增 +1。
无论是只读事务对临时表的操作,还是读写事务对普通临时表的操作,只要有操作动作就会分配一个
事务ID.
所以每个事务都拥有一个唯一的 事务ID,先知道这个事情先,后面要用。
四.UNDO通用日志格式
按照编程惯性,肯定是有一个差不多的类型,来封装管理不同的信息的:
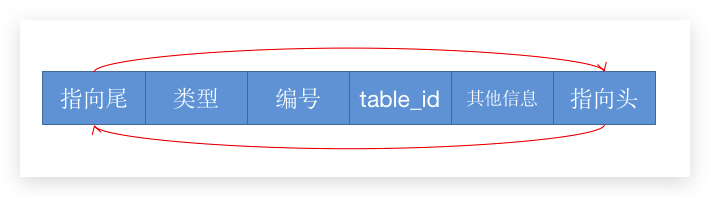
这是一条 undo log 的通用格式,头尾两个指针互相指向,这样可以相互查找上一条或者下一条 undo log。 类型 和 其他信息 是需要对应起来的,不同的类型有不同的信息。 table_id 指的是哪张表的重做记录,每张表都有自己的 id。我们可以通过 SELECT * FROM information_schema.innodb_sys_tables WHERE name = 'imopei/tbusiness_order_self_info' 来查询对应表的 table_id。
五.UNDO日志分类
虽然我们开发的时候对应的数据库操作有 增 删 改,但是在实际对 undo log 分类的时候却只有两大类,一类是 insert undo log,一类是 update undo log。 为啥只有两类,因为 增 是一个从 0 到 1 的过程,在实际做 undo log 的时候还要稍微简单一点,而 改 肯定是 update undo log,那 删 是怎样操作,其实就是把之前所说的 数据行 一个 删除标记 设置为 true,然后加入数据页的 垃圾链表 进行管理,后续如果需要重用空间,就可以直接在 垃圾链表 取出来使用。有点类似于我们业务开发的时候所说的 逻辑删除。 由于 insert undo log 要稍微简单一点,所以我们从这里开始说起。
5.1 insert undo log
假设我们现在对一个表进行插入:INSERT INTO product_info(prod_id, prod_name, prod_status) VALUES(10001, 'iPhoneSE 2020', 'VALID');,prod_id 是一个 INT 类型的主键。 使用上面的通用日志类型存入数据,一个 insert undo log 的日志格式如下:
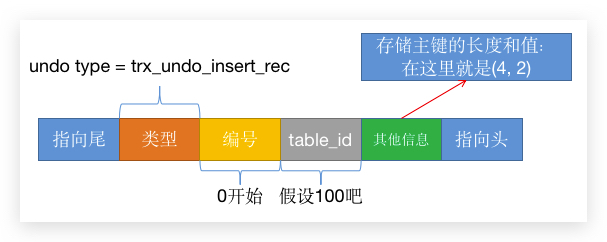
我们可以看到,新增的 undo log 是很简单的,只需要记录新增的数据的 主键prod_id 后续如果需要 回滚数据,直接拿到这段记录的 主键值 然后把对应的 数据行 删掉即可。
5.2 update undo log 之删除
之前说数据页的时候,数据页的 Page Header 有个属性,就是 PAGE_FREE,他代表的是这个数据页 空闲列表 的头部,所有被删除的数据行将会被串起来变成一个 链表,在需要重用这些空间的时候,就可以从这个 空闲列表 取出来使用了。 一个正常的数据页:
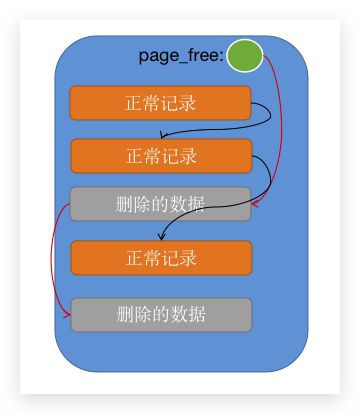
所以删除数据需要经历两个阶段,分割点就在 COMMIT 之前和之后:
- 第一阶段:
标记删除,在事务提交之前,一直都是这个状态,不算正常记录,也不算删除的数据; - 第二阶段:
COMMIT之后,后台线程的PURGE阶段会来清理这条记录的状态,并且顺带修改数据页头部的一些重点参数
所以其实删除只要一条 del_mark_rec 类型的 undo log 就可以了:
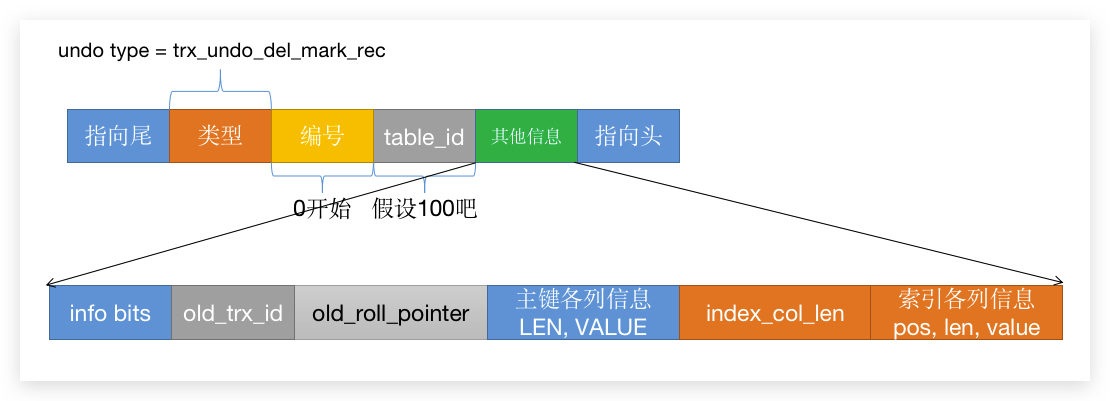
删除的 undo log 就要比插入的麻烦很多: info bits:数据行头信息的前 4 个字节信息,也就是:2个字节 的占位符,delete_flag 和 min_rec_flag old_trx_id:数据行上一个事务的 ID; old_roll_pointer:数据行上一个 undo log 的 ID; 主键各列信息:这个是用来记录聚簇索引需要删除的信息; index_col_len 和 索引各列信息:那么第一个是记录第二个所占用的空间,方便查询第二个参数的内容,后台线程在清理 二级索引 的时候也会方便一些。而 索引各列信息 可以用来清理 二级索引 的数据内容。 那现在我们来和插入串起来:
1 | // 建立一个用户表,指定一个二级索引 |
那现在我们就来操作这个表:
1 | BEGIN; |

步骤:
- 首先,执行了插入语句,
数据行有个列叫做roll_point(图中简化成r_p)指向了新增语句的undo_log; - 然后,执行了删除语句,那么数据行的指针就指向了新的删除
undo_log,然后undo_log的old_roll_pointer被指向第1步的插入语句,最后的情况:
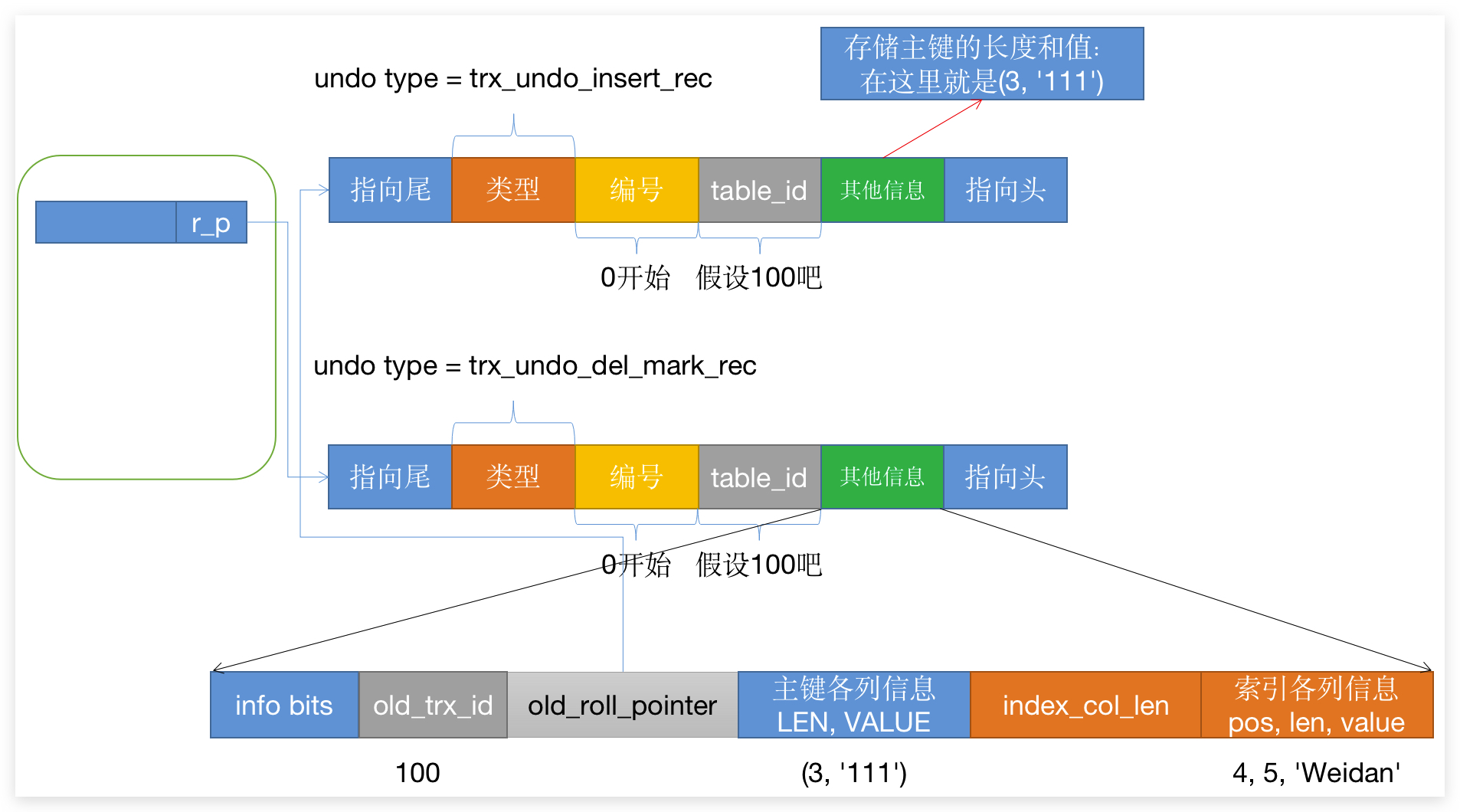
那么我们可以初步的获取到一条记录由 undo_log 串起来的 版本链,这也就是一条记录的不同版本,在后面会说到。
5.2 update undo log 之更新(不更新主键的情况)
UPDATE 的 undo log 内容有点多,分为 更新主键的情况 和 不更新主键的情况。这里先说说 不更新主键的情况。 那么 不更新主键 的地方又要视情况而定:
- 更新后的值跟原来的值的长度一样:就地更新;
- 否则,先删除,再插入新的记录。(这个删除跟上面的删除不一样,而是在用户所在线程中删除,然后再立即插入新的记录<而下面的
完全更新就不一样了,是删除标记,然后由后台线程来清理 >)
首先来看看 undo log 的格式:
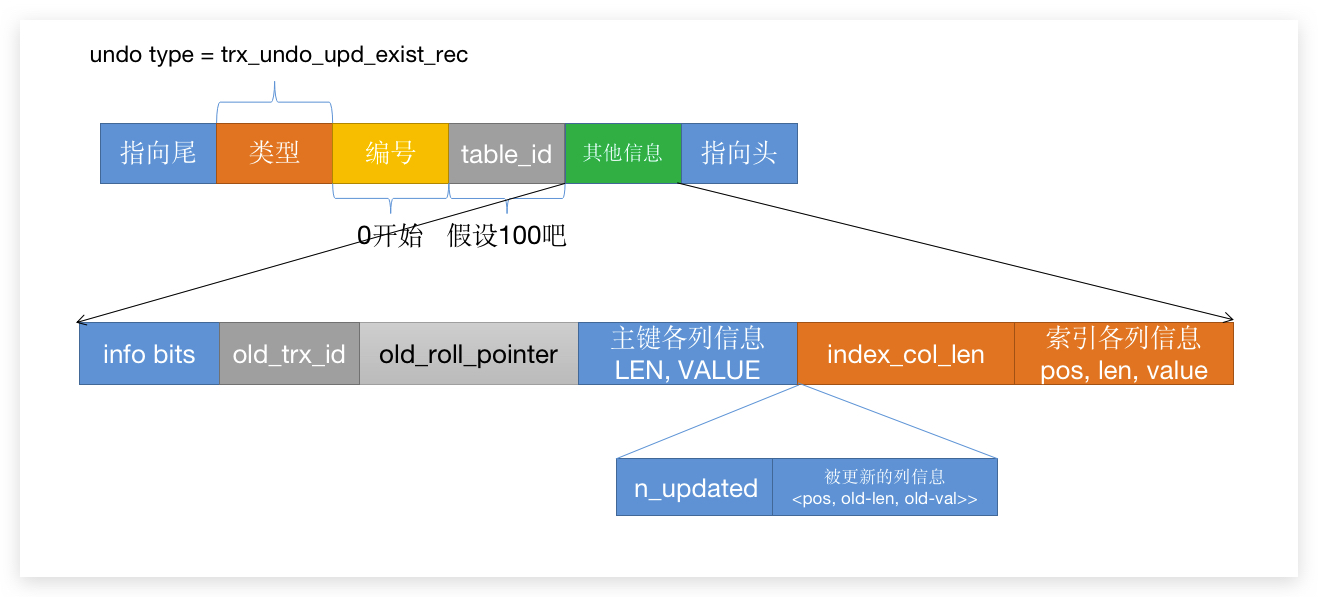 OK,其实上面两个是
OK,其实上面两个是 删除格式,我用了小学的 改错句 方法把新的加上去了。 总的来说呢,跟 删除undo log 作比较,就是多了两个东西,一个是有多少列被更新,一个是这些列的 旧长度 和 旧值
5.2 update undo log 之更新(更新主键的情况)
唯一区别点也说了,就是在删除就记录的时候,会把 需要删除的列进行标记(因为其他事务可能还需要用到这条记录),然后提交的时候会重新变成新的记录 插入,因为主键更新了,就需要更新数据库的 聚簇索引 了,所以得重新当成新的记录看待。 更新内容的版本链表和删除的时候差不多,不演示了(懒…
(我是分割线,上面是日志管理数据,下面是系统管理日志)
六.UNDO LOG数据页链表
6.1 数据页链表结构
万物皆可 链表:
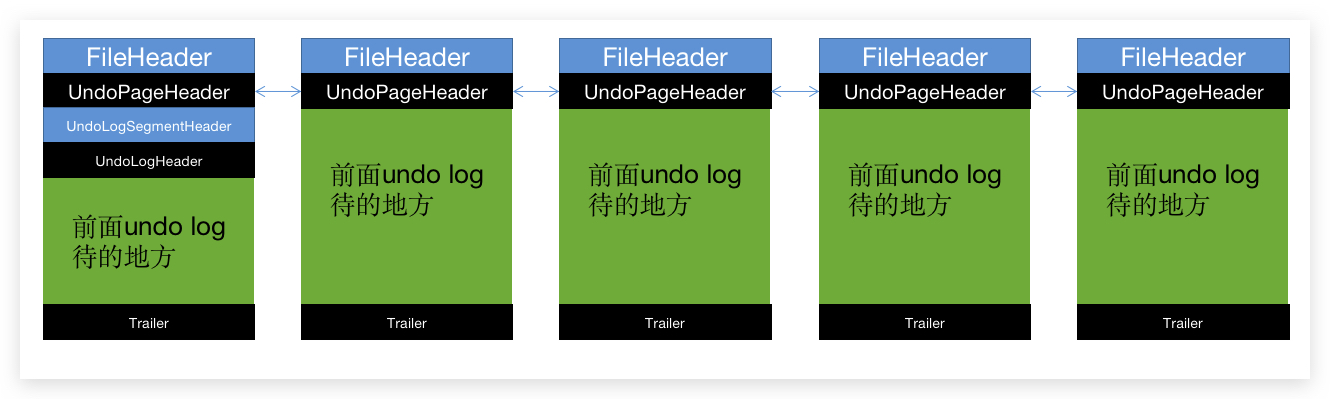
- 上面是一堆
undo log页(InnoDB与磁盘交互的基础); -
UndoPageHeader相互连接,也就是每个箭头都是双向指针; - 第一个
undo log页有undo log segment header,也就是undo页的段开头,这里记录了当前undo log页能否被重用,事务活跃状态等信息; - 每个事务开始,
undo log header会记录事务的相关信息,也就是trx_idtrx_nodel_marklog_start等重要信息 ,分别用来记录事务ID事务编号(先开始的事务小,后的大)是否含有删除标记的undo log日志开始的位置。
6.2 事务并发执行的链表页
那么链表页其实是有分类的,并不会 增删改 都丢在同一个链表:

然后对 普通表 临时表 的操作也要分开,也就是两组上面的图片,不画了。 不过并不是事务一开始就分配的,而是按需分配,比方说一个事务只有插入普通标,那就只有一个上面的链表了。
6.3 undo log页的重用
那么了解到这里,感觉到为了能够 回滚,系统做的事情还是特别痛苦的,分配了一堆空间。 那重用这些空间就变得很迫切了,不然一个数据库系统占用的资源也就太多了吧。 什么时候可以重用:
-
undo页只有一个的时候,事务提交完成(意味着不需要undo log了)那么可以重用这部分空间; - 事务非常小,
undo log占用一个页面的空间不到3/4的时候,可以把新的undo log包括头信息插入到旧的页面里面去(也就是上面图片的绿色部分); - 只有一个页面,并且事务已经提交,并且
只存储新增的undo log的时候; - 而
更新undo log不能删掉,后面还有用;
七.回滚段
我们前面知道,数据多了以后,会再有一个 段 的概念来管理这些数据页。而 回滚页 也是同样的道理。这个段,关联着众多的 回滚页头,也就是上面那幅图的每个链表的第一个页。 那么这个段头其实他自己也是一个 数据页,也就是 16kb。所以他其实只是 FileHeader 里面的类型字段不同而已。

那么一个事务开始了,InnoDB 就可以找到这些 回滚段 类型的 数据页。如果能够申请到 SLOT 就可以继续执行,那如果申请不到的话,就说明系统已经无法再开启事务了。一个回滚段有 1024个 SLOT,在目前我们可以使用的版本中,一般有 128个 回滚段。所以一共有 1024 * 128 =131072 个 SLOT,基本可以满足目前业务需求。那这些 回滚段 又散落在不同的表空间:所以就可以出现一棵树:
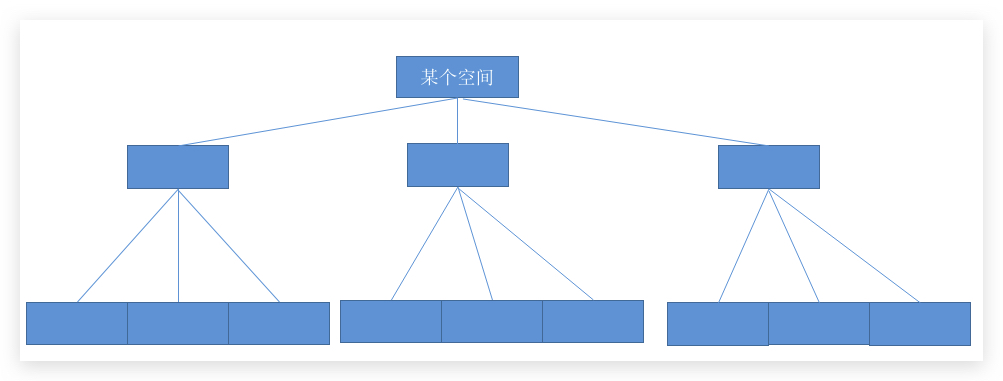
回滚段分类
回滚段也会被分类,因为我们的事务可能只是操作 临时表 的事务,所以这些 undo log 在系统崩溃的时候,可以不用去管他,所以要跟重要的 普通表 的 undo log 分开来处理: 第 1-32 号回滚段就是用来存储 临时表 的 日志 的。
八.小结
这篇主要说了事务回滚中的 undo log,其中的 版本链 就是事务之间隔离的重要组成成分,接下来说。