一个Java程序猿眼中的汇编
一、介绍
在计算机中,CPU只能识别二进制,当需要CPU做事情的时候,都需要通过二进制去指挥CPU做什么事情。古人觉得二进制实在是难以理解,所以才发明了汇编语言以及后面的高级语言,所以汇编语言可以称作为比较接近机器语言的语言了。 当然后面的古人依然觉得汇编语言难以理解,所以发明了C、C++、Java来解决难以理解的问题。所以后面的语言越来越偏于人类自然语言,并且使用面向对象的思想来设计程序。当然这期间经历的事情还挺多:C编译成汇编语言,汇编语言再翻译成二进制语言,这个过程即称为assembling。 学习汇编语言既需要下面两个概念的理解:内存模型和寄存器
二、内存模型
(一)内存模型的介绍
内存通常被程序分为两个部分:堆(Heap)和栈(Stack) 当一个程序开始运行的时候,系统通常会为改程序开辟一块内存空间,而这块内存空间在该程序运行的时候,也会被划分成为上面最常见的两块区域,通常他们的作用如下:
- 堆(Heap):通常被动态的划分,用来存储程序运行的时候需要存储的数据,当程序结束以后,这块内存将被系统重新回收。当C语言中调用
- 栈(Stack):用于存储方法运行中需要使用到的临时变量的空间。Java中的栈,当需要的临时变量如果是对象的情况下,存储的是对象在堆中的引用地址,基本数据类型的话那就是直接存储数据了。
(二)堆空间的使用
(内存模型引用阮老师的图片) 1.当一个程序被启动,系统中会在内存中为改程序划分一块空闲内存:
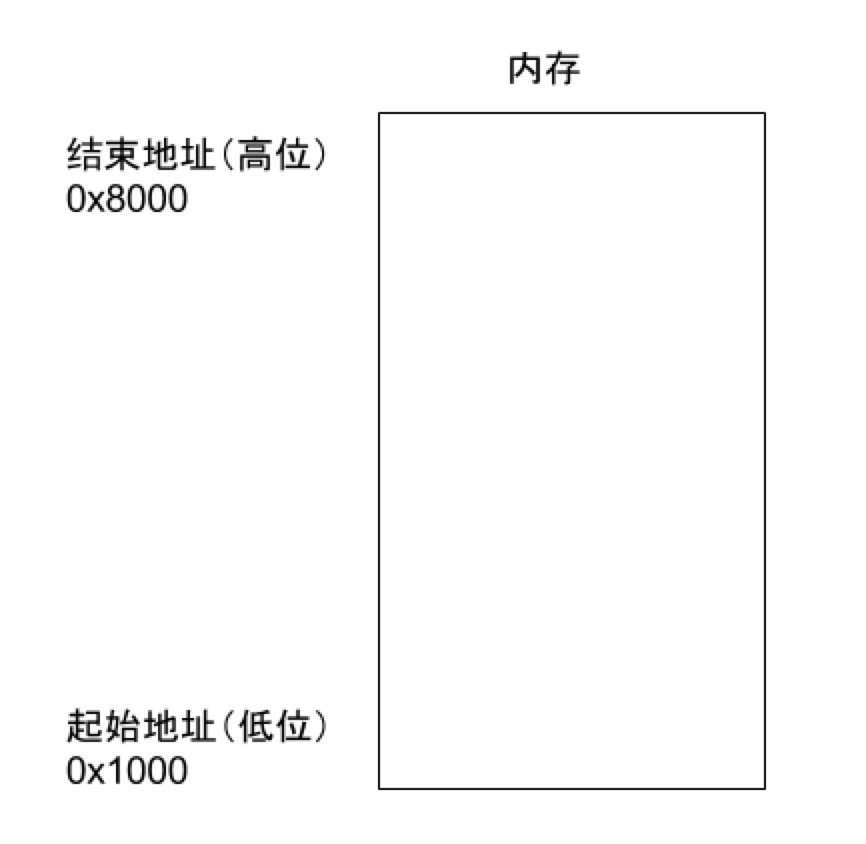
这块内存是从低到高进行划分的,当该程序需要分配对象的时候(使用malloc命令),系统将从这块内存的低位开始,按照对象的大小划分一块内存供这个对象存放:
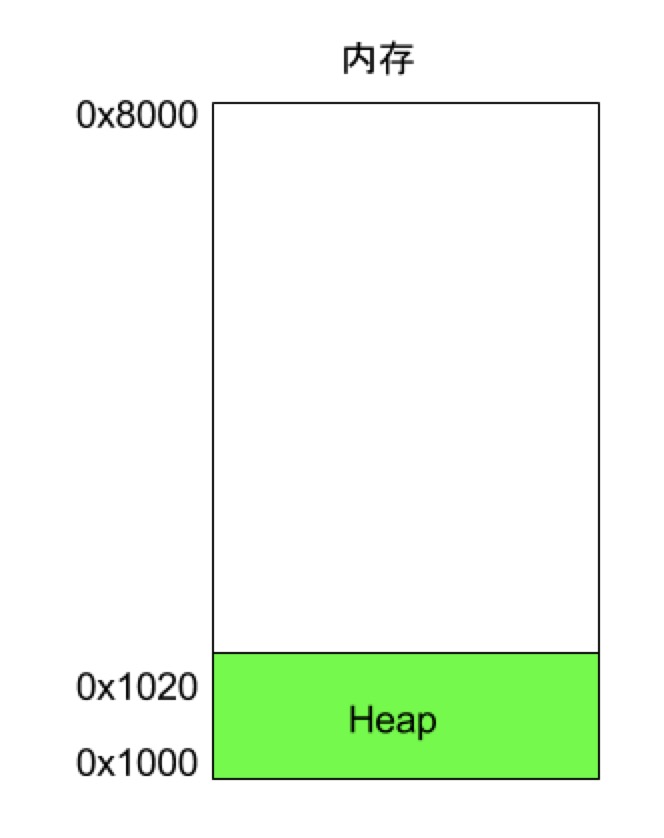
图中的对象中用了32个字节: 具体计算(8进制): 0x1000 + 32 = 0x1020 堆空间必须手动释放或者通过程序的垃圾回收器,如果该对象被GC判定为无用的对象,那么GC将对这块内存进行释放。
(三)栈空间的使用
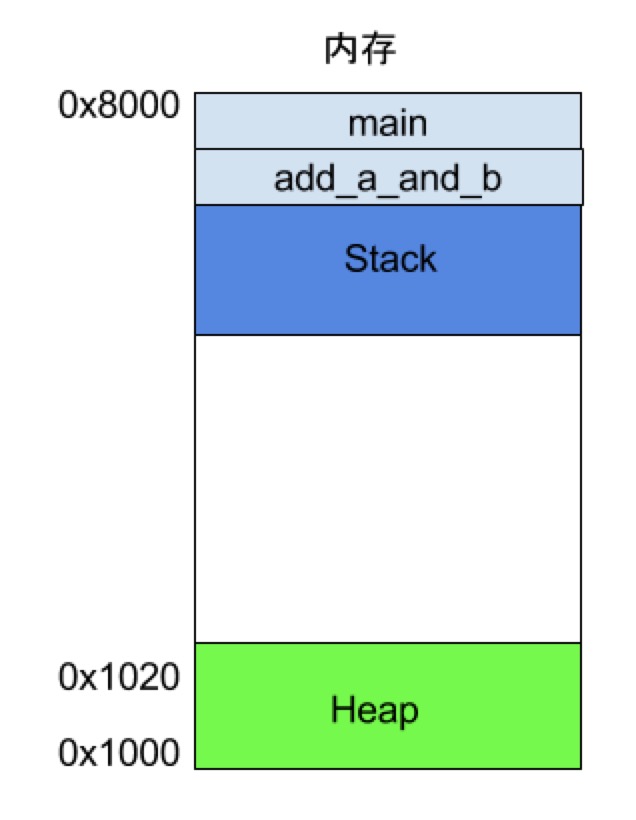
栈空间用于存储一个函数运行过程中需要用到的数据的内存。 栈和堆不同的是:栈是从高位开始占用内存的,而且遵从LIFO (Last-In-First-Out)原则。 为啥是先进后出:因为函数调用的时候,最后一个调用的函数是最先结束的: 举个例子:
1 | int main() { |
在这段代码中,main函数先入栈,其次调用了add_a_and_b(a, b),该函数入栈。那么是不是add_a_and_b(a, b)函数先执行完成,再把结果返回给main方法,main再运行结束。 栈空间:
三、寄存器
(一)寄存器的介绍
我们还要知道的另外一件事情是CPU只负责做事情,并不能够存储任何数据,包括运算过程中需要用到的临时数据,都需要通过缓存、内存以及寄存器来存储。 那么何为缓存:缓存是CPU能够够得到的第一级存储物质,再之是内存。为啥有内存了还需要这些东西呢,因为设计者认为,CPU的速度要远快于内存的速度,如果任何数据都通过去读取和写入内存操作的话,就会拖慢CPU的速度,所以在京东或者其他地方购买CPU的时候,是会出现缓存这个东西的:
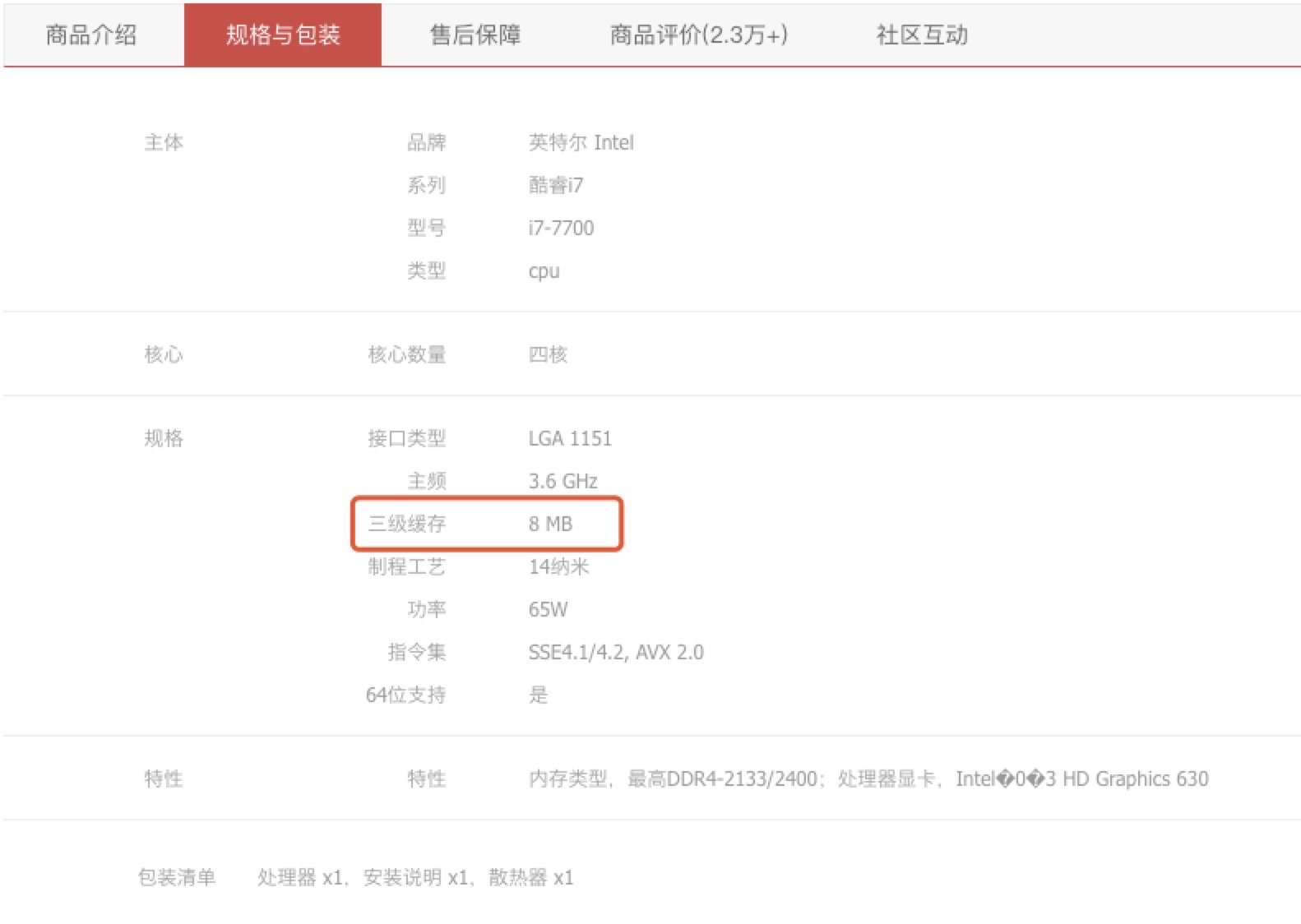
现在普通一点的CPU都会自带一级缓存二级缓存(图中还有三级缓存= =),说的就是这个事情,当然这个缓存也不是越大越好,仔细想想如果这个缓存过大,那么在同步缓存和内存的数据的时候,是不是也会变慢。这个东西和jvm虚拟机中的堆和栈大小是一致的,如果jvm中堆栈过大,放数据是爽很多了,但是在进行垃圾清理的时候就是悲剧了。 接下来还有寄存器的概念:设计者认为每次需要数据的时候去读取数据,都需要寻址读取,那么还是会变慢很多,那如果把数据的地址存放在一个地方,需要的时候直接取出这个地址,然后再在缓存中去取出来,就会快很多,这个过程就是寄存器需要做的事情了。寄存器相当于用于寄放地址的地方,当程序指示CPU去读取什么数据的时候,CPU优先从寄存器中取出数据的地址,然后从缓存读取数据进行运算。 那么计算机运行的过程相当于: 1. 用户告诉CPU启动一个程序 2. 程序把数据放入系统为其开辟的一块内存空间 3. CPU从内存读取数据放入缓存,以及在寄存器放入缓存数据的地址 4. CPU通过协调内存、寄存器、CPU缓存完成用户继续给予的指令。
(二)寄存器的种类
一个CPU都会提供多种寄存器,用于存储不同的数据(不同程序使用不同的寄存器),在早期的x86处理器当中,CPU提供9种不同的寄存器,但是程序中可用的只有7中,其中2中用于做特殊作用:
现在的寄存器已经有100多个了,都变成通用寄存器,不特别指定用途了,但是早期寄存器的名字都被保存了下来。
- EAX
- EBX
- ECX
- EDX
- EDI
- ESI
- EBP
- ESP 记录内存中栈空间的地址
- EIP 记录当前指令执行的位置
汇编语言要做的事情就是指挥这些寄存器中做的动作。
四、一个简单的程序
现在使用一个C语言的代码来表述计算机做了什么事情:
1 | int main() { |
运行编译,他将会被编译成以下的汇编语言:
1 | _main: |
程序运行的时候,内存模型如下:

第一步:当main开始运行的时候,需要先把临时的值压入栈内存中: 所以有两个参数3和2被压入占中,这就是栈内存中前两个的值的地址。 第二步:临时变量已经准备好了,我们要把main函数压入栈中,因为main函数一共有四条指令,而一条指令只用4个字节,所以一共有16个字节被压入栈中 第三步:因为在函数_add_a_and_b中,我们用到了中间寄存器用来计算ebx,所以ebx被压入栈中。 经过了这三个步骤,那么esp(程序运行指针)被多次往下移动了16个字节,其中包括main函数四条命令4个字节以及两个参数8个字节,还有一个临时寄存器使用了4个字节, 当然图中那么画还不够具体。
首先main函数入栈,将参数推入栈中。 然后运行到了call _add_a_and_b步骤,函数入栈,继续刚刚的操作 这里因为call _add_a_and_b中有个步骤是推入一个中间寄存器,所以esp在call部分又向下推一个4字节的空间。 所以在函数当中,需要访问第一个参数的时候,应该是通过esp + 8去获取,第二个就更需要esp + 12去获取了 这里有个重点,就是我们如何保证我们使用的寄存器不会被其他程序的执行而让我们的程序运行过程中遭到破坏。 很简单:当我们需要用到一个寄存器的时候,我们把一个寄存器的副本压入栈中,然后我们即可在函数中对这个寄存器进行使用以及清理。
参考
阮一峰《汇编语言入门教程》
Introduction to reverse engineering and Assembly.
堆栈的工作原理